|
資料來源:
https://towardsdatascience.com/the-actual-difference-between-statistics-and-machine-learning-64b49f07ea3
我厭倦了在社交媒體上和我的大學裡幾乎每天都在重複這場辯論。通常這伴隨著模糊的陳述來解釋這個問題。雙方都為此感到內疚。希望在本文結束時,您將對這些有些模糊的術語有一個更明智的立場。
論據
機器學習已經存在了幾十年,這與普遍的看法相反,。由於其龐大的計算要求和當時存在的計算能力的限制,它最初被迴避使用。然而由於資訊爆炸產生的大量數據,近年來機器學習得到了復起。 那麼,如果機器學習和統計學是同義詞,為什麼沒有看到每所大學的每個統計學系都關閉或轉變為“機器學習”系呢?因為兩者不一樣!
關於這個話題,我經常聽到一些含糊不清的說法,最常見的說法是這樣:
“機器學習和統計學之間的主要區別在於它們的目的。機器學習模型目的在做出最準確的預測。統計模型目的用以推論變數之間的關係。”
雖然這在技術上是正確的,但它並沒有給出特別明確或令人滿意的答案。機器學習和統計之間的主要區別的確是它們的目的。除非你精通這些數理概念,否則認為機器學習都是關於準確預測,而統計模型是為推理而設計的,這幾乎是一種毫無意義的說法。
首先,我們必須明白統計學和統計模型是不一樣的。統計學是對於數據的數學研究。除非您有數據,否則您無法進行統計。統計模型是一種數據模型,用於推斷數據中的關係,或建立能夠預測未來值的模型。通常這兩者是同時進行的。
所以實際上有兩件事我們需要討論:第一,統計學與機器學習有何不同,第二,統計模型與機器學習有何不同。
為了使這一點更加明確,有很多統計模型可以進行預測,但預測的準確性並不是它們的強項。同樣,機器學習模型提供了不同程度的可解釋性,從高度可解釋的lasso
迴歸到難以理解的神經網絡,但它們通常會犧牲解釋性,以換取預測能力。
從高層的角度來看,這是一個好的答案。對大多數人來說已經足夠了。然而,在某些情況下,這種解釋讓我們誤解了機器學習和統計建模之間的差異。讓我們看一下線性迴歸的例子。
統計模型與機器學習-線性迴歸例子
對我而言,統計建模和機器學習中使用的方法的相似性使人們認為它們是相同的一件事。這是可以理解的,但根本不是真實。最明顯的例子是線性迴歸的例子,這可能是造成這種誤解的主要原因。線性迴歸是一種統計方法,我們可以訓練線性迴歸器(機器學習)並獲得與統計迴歸模型相同的結果,目的在最小化數據點之間的平方誤差。
我們看到在一種情況下,我們做了一種叫做“訓練”模型的事情,其中涉及使用數據的一個子集,在訓練期間,稱為測試集,並且我們用其他數據“測試”這些數據,我們才知道此模型的性能如何。在這種情況下,機器學習的目的是在測試數聚上獲得最佳性能。
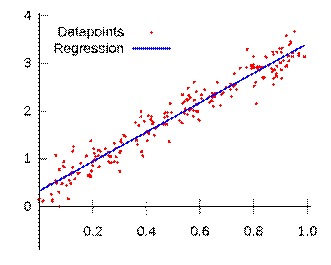
對於統計模型,我們找到一條線,使所有數據的變異數誤差最小化。其假設是數據是線性迴歸量,添加了一些隨機噪聲,這通常是高斯性質。不需要訓練和測數據。對於許多情況,尤其是在研究中(例如下面的感測器示例),我們模型的重點是描述數據與結果變數之間的關係,而不是對未來數據進行預測。我們將此過程稱為統計推斷,而不是預測。但是我們仍然可以使用此模型進行預測,這可能是您的主要目的,但評估模型的方式將不涉及測試數據,而是涉及評估模型參數的重要性和穩健性。
(註解):此段內容不正確。統計學中迴歸分析之預測性能,已有詳細技術。
監督機器學習的目的是獲得一個可以進行重複預測的模型。通常不關心模型是否可解釋。儘管我個人建議始終進行測試,以確保模型的預測確實有意義。機器學習就是關於結果,它很可能在一家你的價值完全取決於你的表現的公司工作。然而統計建模更多的是尋找變數之間的關係,以及這些關係的重要性,同時也滿足預測的需要。
為了給出具體例子區別這兩個程序之間,舉一個個人例子。白天我是一名環境科學家,主要處理感測器數據。如果我試圖證明感測器能夠反應某種刺激(例如氣體濃度),那麼我會使用統計模型來確定信號反應是否具有統計顯著性。我會嘗試瞭解這種關係並測試它的可重複性,以便我可以準確地表徵感測器反應,並根據這些數據進行推斷。我可能會測試的一些事情以反應這些訊號實際上是否是線性。反應是否可以歸因於氣體濃度而不是感測器中的隨機噪聲等。
相比之下,我還可以獲得 20
個不同感測器的陣列數據,我可以使用它來嘗試預測這些新表徵的感測器的反應。如果您對感測器不太了解,這可能看起來有點奇怪,但這是目前環境科學的一個重要領域。一個包含
20
個不同變數的模型來預測我的感測器的結果,顯然都是關於預測,不希望它特別具有可解釋性。由於化學動力學產生的非線性以及物理變數與氣體濃度之間的關係,該模型可能會像神經網絡一樣更加深奧。我希望這個模型有其原理意義,但只要我能做出準確的預測,我就會很高興。
如果我想證明我的數據變數之間的關係,具有一定程度的統計顯著性。我可以將其發表在科學論文,我會使用統計模型而不是機器學習。這是因為我更關心變數之間的關係,而不是做出預測。做出預測可能仍然很重要,但是大多數機器學習演算法缺乏可解釋性,因此很難證明數據之間的關係。這實際上是現在學術研究中的一個大問題,研究人員使用他們不理解的演算法並獲得似是而非的推論。
資料來源:Analyst
Vidhya
儘管使用了類似的方法來實現目標。應該清楚的是,這兩種方法的目標是不同的。機器學習演算法的評估使用測試數據來驗證其準確性。而對於統計模型,通過置信區間、顯著性檢驗和其他檢驗分析迴歸參數可用於評估模型的合法性。由於這些方法產生相同的結果,因此很容易理解為什麼人們會認為它們是相同的。
統計與機器學習-線性迴歸示例
我在這個表面上詼諧的 10
年,這種誤解很好地概括比較統計和機器學習的挑戰中。然而,僅僅基於它們都利用相同的概率基本概念這一事實,將這兩個術語混為一談是不合理的。例如如果我們基於這個事實做出機器學習只是美化統計的陳述,我們也可以做出以下陳述。
物理學只是被美化的數學。
動物學只是美化的集郵。
建築只是美化的沙堡建築。
這些陳述,尤其是最後一個陳述非常荒謬,並且都基於這種將基於相似的術語混為一談的想法。
實際上,物理學是建立在數學之上,它是應用數學來理解現實中存在的物理現象。物理學還包括統計學的各個方面,而現代的統計學通常是由
Zermelo-Frankel
集合論和測度論組成的框架建立的,以產生概率空間。它們都有很多共同點,因為它們來自相似的起源,並應用相似的想法,來得出合乎邏輯的結論。同樣建築和沙堡建設可能有很多共同點。雖然我不是建築師,所以我無法給出明智的解釋,但它們顯然不一樣。
為了讓您了解這場辯論的範圍,實際上在 Nature Methods
上發表了一篇論文,概述了統計學和機器學習之間的區別。這個想法可能看起來很可笑,但這種程度的討論是必要的,這也是有點可悲。
意義點:統計與機器學習
統計學從樣本中得出總體推斷,機器學習發現可概括的預測模式。
Points of Significance:
Statistics versus machine learning
Statistics draws
population inferences from a sample, and machine learning finds
generalizable predictive patterns. Two…
www.nature.com
在我們繼續之前,我將快速澄清另外兩種機器學習和統計相關的常見誤解。這些是:1.人工智慧不同於機器學習,2.數據科學不同於統計學。這些都是相當無爭議的問題,所以它會很快。
數據科學本質上是應用於數據的計算和統計方法,這些數據可以是小型或大型數據集。這還可以包括探索性數據分析之類。其中數據被檢查和可視化,以幫助科學家更好地理解數據並從中做出推斷。數據科學還包括數據整理和預處理等內容,因此涉及到某種程度的電腦科學。因為它涉及編碼、建立數據庫、Web
服務器等之間的連接。
您不一定需要使用電腦進行統計,但沒有電腦就無法真正進行數據科學。您可以再次看到,儘管數據科學使用統計數據,但它們顯然並不相同。同樣,機器學習與人工智慧不同。事實上機器學習是人工智慧的一個子集。這是非常明顯的,因為我們正在訓練一台機器,以根據以前的數據對某種類型的數據進行概括推斷。
機器學習建立在統計之上
在討論統計學和機器學習的不同之處之前,讓我們先討論一下相似之處。我們已經在前面的部分中談到了這一點。機器學習建立在統計的框架之上。這應該是顯而易見的,因為機器學習涉及數據,並且必須使用統計框架來描述數據。然而擴展到大量粒子的熱力學其統計力學也建立在統計框架之上。壓力的概念其實是一個統計,溫度概念也是一個統計。如果你覺得這聽起來很可笑。但是也也很公平,它確實是真的。這就是為什麼你不能描述一個分子的溫度或壓力,這是荒謬的。溫度是分子碰撞產生平均能量的表現。對於有足夠多的分子,我們可以描述房屋或室外的溫度。但是你會承認熱力學和統計學是一樣的嗎?不,熱力學使用統計數據來幫助我們以傳輸現象的形式理解功和熱的相互作用。
事實上,除了統計數據之外,熱力學還建立在更多項目。同樣,機器學習也藉鑑了許多其他數學和電腦科學領域,例如:
來自數學和統計學等領域的機器學習理論。
來自最佳化、矩陣代數、微積分等領域的機器學習演算法。
來自電腦科學和工程概念的 ML
實現(例如內核技巧、特徵散列)。
當一個人開始在 Python 上編碼並引用
sklearn庫,並開始使用這些演算法時,很多這些概念都被抽像出來。因此很難看出這些差異。在這種情況下,這種抽象導致了對機器學習實際涉及內容的一種無知。
統計學習理論-機器學習的統計基礎
統計學和機器學習之間的主要區別在於統計學完全基於概率空間。您可以從集合論中推導出全部統計數據。它討論了我們如何將數字分組到稱為集合的類別,然後對該集合施加度量以確保所有這些的總和值為
1。我們稱其為概率空間。
除了這些集合和度量的概念之外,統計學對宇宙沒有其他假設。這就是為什麼當我們用非常嚴格的數學術語指定概率空間時,我們指定了三件事。
一個概率空間,表示為(Ω, F, P),由三部分組成:
樣本空間Ω
,它是所有可能結果的集合。
一組事件F
,其中每個事件都是包含零個或多個結果的集合。
事件的概率分配, P;即從事件到概率的函數。
機器學習基於統計學習理論,該理論仍然基於概率空間的公理概念。該理論是在1960年代發展起來,並在傳統統計數據的基礎上進行擴展。
機器學習有好幾種類別,因此我在這裡只關注監督學習,因為它最容易解釋。監督學習的統計學習理論如下:,我們有一組數據,我們將其表示為S
= {(xᵢ,yᵢ)}。這基本上說我們是一個由n
個數據點組成的數據集,每個數據點都由我們稱為特徵數值描述。這些值由x
提供,這些特徵通過某個函數映射(mapped)給我們值y。它表示我們知道我們有這些數據,我們的目標是找到將x值映射到y值的函數。我們將可以描述這種映射的所有可能函數的集合,稱為假設空間。
為了找到這個函數,我們必須給演算法一些方法,以“學習”解決問題的最佳方法。這是稱為損失函數。因此對於我們擁有的每個假設(提議的函數),我們需要評估該函數的執行情況,藉由此函數對所有數據的預期風險值。
預期風險本質上是損失函數乘以數據概率分佈的總和。如果知道映射的聯合概率分佈,就很容易找到最佳函數。然而這通常是未知,因此我們最好的辦法是猜測最好的函數,然後憑經驗決定損失函數是否更好。我們稱之為經驗風險。
我們可以比較不同的函數,並尋找一個假設能夠給我們最小預期風險。此假設為數據所有假設的最小值,稱為下確界。然而,該演算法有欺騙的傾向。因為是通過過度適配數據來最小化其損失函數。這就是為什麼在基於訓練集數據學習得到一個函數之後,該函數必須在另一個測試數據集上進行驗證。這些數據沒有出現在訓練術據集中。
我們剛剛定義機器學習的性質引入了過度適配的問題,並證明了在執行機器學習時需要訓練數據集和測試數據集。這不是統計學的固有特徵,因為我們並沒有試圖最小化我們的經驗風險。
(註解):統計迴歸已有此訓練與測試之概念。
選擇最小化經驗風險的函數的學習演算法稱為經驗風險最小化。
例子
以簡單的線性迴歸為例的。在傳統意義上,我們試圖最小化一些數據之間的誤差,以便找到一個可以用來描述數據的函數。在這種情況下,我們通常使用變異數誤差。我們將誤差平方,以便正負誤差不會相互抵消。然後我們可以以封閉形式的方式求解迴歸係數。碰巧的是,如果我們將損失函數作為變異數誤差,並按照統計學習理論的支持進行經驗風險最小化,我們最終會得到與傳統線性迴歸分析相同的結果。
這只是因為這兩種情況是等價的,就像對同樣的數據執行最大概似估計也會得到同樣的結果。最大概似估計有不同的方式來實現相同的目標,但沒有人會爭論說最大概似估計與線性迴歸相同。在最簡單的情況,顯然無助於區分這些方法。
另一個重要的一點是,在傳統的統計方法中,沒有訓練和測試集的概念。註解(不正確)。但我們確實使用指示標準來幫助我們檢查模型的性能。因此評估程序是不同的,但兩種方法都能夠為我們提供統計上穩健的結果。
還有一點是,這裡的傳統統計方法為我們提供了最佳化解,因為該解具有封閉形式。它沒有測試任何其他假設,並收斂到一個解決方案。然而機器學習方法嘗試了一堆不同的模型並收斂到最終假設,這與迴歸演算法的結果一致。
如果我們使用不同的損失函數,結果將不會收斂。例如如果我們使用了鉸鏈(hinge)損失。那麼結果將不一樣。使用標準梯度下降無法微分,因此需要其他技術,如近端梯度下降(like
proximal gradient descent)。
可以通過模型的偏差來進行最終的比較。人們可以要求機器學習演算法測試線性模型,多項式模型、指數模型等。看看這些假設是否更適合我們的先驗損失函數的數據。這類似於增加相關假設空間。在傳統的統計意義上,我們選擇一個模型並可以評估其準確性,但不能自動使其從
100
個不同的模型中選擇最佳模型。顯然模型中總是存在一些偏差,這源於最初的演算法選擇。這是必要的,因為找到對數據集最優的任意函數是一個
NP-hard 問題。
那麼哪個更好呢?
這實際上是一個愚蠢的問題。就統計學與機器學習而言,沒有統計學就不會存在機器學習。但是機器學習在現代非常有用,因為自資訊爆炸以來人類可以獲得大量數據。
比較機器學習和統計模型有點困難。你使用哪個,很大程度上取決於你的目的是什麼。如果您只是想建立一種可以高精度預測房價的演算法,或者使用數據來確定某人是否可能感染某些類型的疾病,那麼機器學習可能是更好的方法。如果您試圖證明變數之間的關係或從數據中進行推論,那麼統計模型可能是更好的方法。
如果你沒有很強的統計學背景,你仍然可以學習機器學習並利用它。機器學習庫提供的抽象使得不是非專家也很容易使用它們,但你仍然需要一些了解潛在的統計思想,以防止模型過度適配並且給出似是而非的推論。 |