|
資料來源:
https://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.80.4413&rep=rep1&type=pdf
摘要:資訊已經成為一種重要的商業商品,甚至可能是未來最重要的產品。雖然我們已擁有成熟的數據存儲技術,但資訊提取分析非常耗時,並且需要熟練的人工干預。機器學習演算法通過提供自動化資訊發現過程機制來增強統計分析。這些演算法也往往更容易被最終用戶和各領域專家存取。兩種分析方法正在趨向相同,領域互有可取之處
1.簡介
隨著電腦的日益普及,以機器可讀形式存儲的科學和商業數據的數量也在不斷增加。在1989
年,估計全世界存在 5x106 個電腦數據庫。現在估計世界上的資訊量每
20 個月增加一倍,從那時起,數據庫的規模和數量很可能都急劇增長(Frawley ,
1991
)。不幸的是,與此同時,數據生成和數據理解之間的差距也在擴大。積累數據通常不是問題。事實上許多組織實際上擁有的數據比他們自己知道的要多得多!傳統上,統計技術已被用於從數據中提取隱含資訊。但有效的統計分析需要具備的數學背景,很少有數據庫管理員或領域專家。此外統計分析非常耗時,因為分析人員必須單獨制定和測試每個假設。這是一項艱鉅的任務,因為即使是中等規模的數據庫也隱含著許多可能性。機器學習技術的開發是為了反應當前對發現資訊中過程自動化的迫切需求。通常機器學習演算法允許用戶指定所需的資訊類型,自動進行分析。或在最少的人力指導下進行。機器學習自動化生成假設,以及它們的測試。此自動化至少部分,如果不是全部。
這兩種數據分析方法是互補的,而不是相互矛盾的。機器學習演算法具有良好的數學基礎,並且許多演算法直接將統計數據納入其演算法。統計技術(特別是
CART
演算法)已經獨立開發,它們與機器學習基本相似,並產生相似的輸出(例如決策樹和場域的規則描述)。兩種類型分析的模型驗證技術是相同的。
本文探討了機器學習和數據統計分析之間的重疊。第 2 節討論了這兩種方法之間的共同點,第
3 節考慮了為給定數據集選擇最佳分析技術的問題。
第
4 節為結論。
2.機器學習與統計研究的共同性
數據分析方法通常可分為探索性或驗證性。
探索性技術在數據中尋找“有趣的”或“不尋常的”模式,而驗證性分析只是。假設數據中存在模式,分析確認或否認它的存在
[Parsaye 和 Chignall, 1993]。T
檢驗和變異數分析是驗證性分析檢驗的示例,因子分析是一種常見的探索性技術。
機器學習演算法主要是探索性的。本文將關注最常見的演算法類型:監督學習方案,它通常生成決策樹或
if-then 規則,通過單個屬性對實例(數據元組)進行分類。圖 1
說明了這種範式(Witten 等, 1993)。該演算法的輸入是一個實例的平面表。其中表的每一行對應於問題場域中的一個唯一對象。在這裡,每條線代表一位眼科醫生的患者,以該患者的各種特徵用於確定該人是否應該戴硬性隱形眼鏡、軟性隱形眼鏡或根本不戴隱形眼鏡。

圖
1. 決策樹和規則(取自 Witten 等,
1993 )
機器學習演算法試圖總結或概括眼科醫生的分類決定。從上到下讀取決策樹,樹的每個分支代表一個關於分類數據實例值的查詢。例如,(1b)
中決策樹的第一個分支提出了一個問題:“患者的淚液產生率是否降低了?” 如果答案為“是”,則此診斷患者不能耐受隱形眼鏡,否則,採用“d=2”分支並繼續查詢。生產規則被解釋為簡單的“If..Then”語句,用戶通過將該人的特徵與規則“If”部分相匹配以對新患者進行分類。請注意,不同的演算法可以從同一數據集生成不同的規則或是不同的決策樹。
雖然這些歸納、探索性方法主要與人工智慧/機器學習研究社群相關聯,但統計學家對歸納學習的興趣在
30 年內很少。自引入 CART 分析系統
(Breiman et al, 1984) 以來,統計歸納學習在統計學中得到了更多的重視,這是一種類似於
ID3 的獨立開發的演算法。事實上,分類樹軟體在過去兩年內已被納入多用途統計軟體套件,如
SPSS 和 S(White
和 Liu, 1994)。
統計方法通常直接結合到許多機器學習演算法。統計分析通常是最佳化決策樹/規則建立演算法的基礎;例如,Quinlan
的 ID3 使用卡方檢驗來決定是否應將屬性添加到分類樹中(Quinlan,
1979)。一旦生成了模型,它可能會過度適配了訓練數據,包含它在訓練數據上產生準確分類結果,其過度具體的規則,但不足夠廣泛化在新數據上充分執行。為了克服這個問題,已經開發了修剪過度適配決策樹的方法。這些方法通常基於樹分支的統計性能(Quinlan,
1986)。這是兩個學科之間加強交流所帶來的好處。是一個特別恰當的例子,因為機器學習研究人員最初沒有意識到過度適配和建立過大決策樹的問題,並且顯然重新發現了這個問題與其獨立解決方案(White和Liu,
1994)。
機器學習從統計學中獲得的最直接好處,可能是大量借用的模型驗證技術。例如n倍交叉驗證和引導。雖然早期的機器學習文獻側重於新演算法的開發。但隨著該領域的成熟,重點開始轉向理解現有演算法並以更有原則的方式應用這些演算法。來自統計學的成熟方法可以直接適用於這些問題(White
和 Liu, 1994)。
作為回報,人工智慧社群以自己的技術為統計領域做出貢獻。主要是使得計算成本高昂的演算法,在現實世界應用中更加實用。例如,自動化假設生成的主要困難,是通常可以產生太多的概括,其中只有一小部分是分析師感興趣的,或者可以在合理的時間內進行探索。人工智慧可以通過深入理解狀態空間搜索技術,和使用啟發式方法來修剪搜索空間,來緩解這個問題。
人工智慧技術應用的第二個重要例子是基於案例推理和基於實例學習的兩個發展。這兩種技術都基本於近鄰演算法,該演算法可以追溯到
1950
年代初期,並已被統計界深入研究。但是此最近鄰演算法的存儲需求過大情況限制其應用下,機器學習技術顯著降低了存儲成本,但代價是學習率和分類準確度略有下降(Aha
et al, 1991; Kolodner, 1993)。這種權衡是機器學習研究的典型特徵,它傾向於近似演算法,其執行效率遠高於精確演算法,同時產生的分類或預測只差一點。
3.分析師如何在統計和機器學習技術之間進行選擇?
在機器學習和統計演算法之間的選擇,應該使用哪個方法來分析特定的數據集?此外如果選擇機器學習,那麼在現有的許多演算法中,哪一個會為該數據集產生最可靠的結果?
第一個問題的直接答案通常在於所需結果的自然性質。Chiogna (1994) 指出,“機器學習領域開發的符號技術,傾向於對新觀察的分類問題給出確定性的答案;統計技術側重於估計可能結果的概率。此外統計模型傾向於針對連續屬性進行分析,而機器學習模型通常適用於離散屬性將連續值聚集成一組有限的離散值。
因此統計方法通常為分類提供內插值或外插估計值(例如,“對於給定的參數,小麥預期產量為
5.63 蒲式耳/英畝”),而機器學習模型通常提供預測範圍(例如,“預期小麥產量低,其範圍在
[0, 8] 蒲式耳/英畝的範圍內”)。Note:外插估計之觀點部正確。
數據分析演算法(統計或機器學習)的主要性能標準是系統模型產生的分類錯誤率。大多數新機器學習演算法的描述,都是通過在機器學習數據存儲庫中的一個或多個數據庫上測試其分類能力,來表明新技術的有效性。機器學習數據庫存儲庫是Jrvine大學維護的一個大型數據集測試平台。機器學習作為一個領域,因提供的演算法評估相對較少,以及未能將機器學習技術與其他類型的數據分析區分。(非正式地被稱為“一個數據集,一個演算法或一個演算法,一個數據集”綜合症)而受到批評。然而,最近已經對機器學習和統計技術的相對有效性進行了更正式的實證研究(Feng,
1993; Weiss 和 Kulikowsi, 1992; Michie 等,
1994)。其中最值得注意的是 StatLog 項目(Michie
等, 1994)。StatLog
將 20 個機器學習、統計和神經網絡分析程序中的每一個應用到
20 個數據集,以嘗試改進以前進行的臨時或小規模評估。
無足為奇的,在 StatLog
試驗中沒有一種技術成為勝利者。發現使用數據分析技術的結果取決於三個因素:“技術的基本品質和適當性;該技術作為電腦程序的實際實施;以及用戶從技術中獲得最佳效果的技能”(Michie,
1994, 第 5
頁)。第二個因素是一個問題就像窮困一樣,將永遠伴隨著我們。隨著機器學習工具箱或工作台變得更廣泛可用,這種情況將得到緩解。允許分析師使用標準且經過良好測試的通用演算法實現(Holmes
等, 1994
)。第一個因素目前是一個研究課題。即使在更成熟的統計學領域,選擇分析技術也是一門藝術。這個問題在機器學習中更為尖銳,演算法的基本特徵還沒有被很好地理解。
第三個因素是用戶的技能。對機器學習特別重要。這種類型的數據分析主要優勢之一是它的實現特別適合各領域專家使用,而不是數據分析專家。機器學習演算法的決策樹和
if-then 規則輸出比統計軟體的標準輸出更具可讀性。例如,考慮對圖 1
中顯示的 Fisher 經典 Iris
數據庫的分析(取自 Parsaye 和
Chignell, 1993 )。該數據庫包含 150 條記錄,三種鳶尾花(Setosa、Versicolor
和 Virginica)各有 50
條記錄。每條記錄包含四個屬性:花瓣和萼片長度,以及花瓣和萼片寬度。目的是使用這些特徵按物種對Iris進行分類
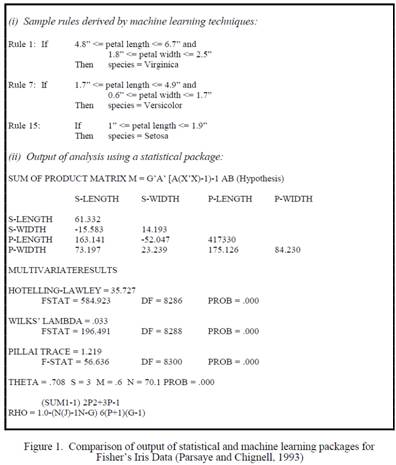
圖
2. 統計和機器學習軟體的輸出比較Fisher
的Iris數據(Parsaye
和 Chignell, 1993 )
顯然外行人更容易理解規則!此外該數據庫的概括通過規則而不是方程式,更方便地總結。規則描述的形式是“當這些屬性具有這些值時,您可以預期花是物種
X”,而統計軟體以不太易於理解的格式提供資訊,例如“如果將花瓣長度乘以
3 並添加到花瓣寬度,得到的數字在 12 到
15 之間,那麼這朵花最有可能是 X 種”(Parsaye
和 Chignell, 1993, 第
197 頁)。(註:不倫不類之比較)
Parsaye 和 Chignell
還提供了一些案例研究,說明了人性化輸出的重要性。這些研究的基本主題是,最終用戶可以比統計顧問更及時(而且通常更便宜)進行有用分析。當然這並不是說機器學習會使統計學家過時!相反地對於定義明確的問題的爭論,允許領域專家直接調查他們自己的數據會更為有效。
最後,兩種類型的輸出之間的差異,不僅僅是表示問題:機器學習規則是基於價值的,而統計結果是基於趨勢的(“變量
A 會隨著變量 B 的增加而增加”)。顯然這兩種方法在本質上都不是最優越的。給定方法對於問題的適用性,取決於問題的性質。
4.結論
統計和機器學習試圖解決數據分析中的許多相同問題,並且已經開始在他們的方法上趨向相同。自 1980
年代後期以來,通過正式努力在兩個領域傳播新成果並促進跨學科合作,這種融合已得到了加強。這些目標的顯著場所包括一年兩次的人工智慧和統計會議,由歐洲機器學習會議贊助的機器學習和統計研討會,以及統計會議中包含的眾多機器學習會議。
這兩個領域都可以相互提供很多東西。在機器學習中,數據的初步統計分析在實際機器學習應用的描述中變得越來越普遍。令人吃驚的發現,推動了這一趨勢,即基於單個屬性做出決策的分類器,通常表現得與更複雜的演算法一樣好!至少這個結果部分原因是許多標準測試數據庫已包含非常簡單的底層結構(Holte,
1993)。這一結論得到了統計分析的證實。統計可視化和數據平滑/聚類方法也被正式納入機器學習工具箱和工作台(Tsatsarakis
和 Sleeman,1993;
Holmes 等, 1994)。與第 2
節中描述的數據過度適配的經驗一樣,機器學習社群似乎正在重新發現統計學家早已了解的問題。也許這一次數學解決方案會被更快地採用!
機器學習可以為數學專業知識相對較少的最終用戶,提供定制輸出的經驗。雖然期望一個天真的用戶,充分分析各種數據集顯然是危險的。但經驗表明,領域專家可以通過最少的訓練產生有用且及時的分析(Parsaye
和 Chignell, 1993)。由於目前有大量未開發的數據庫積累,數據庫管理員和用戶的參與可能可以從這些原始數據中提取資訊的最佳技術。
有趣的是,機器學習最終可能會提供有關各種分析演算法,對給定數據集的適用性的原資訊。性能資訊是從評估程序(例如
StatLog)中積累的,該程序通過某些特徵(例如屬性類型、未知值的數量等)表徵數據集。並將這些與分析技術的分類準確性相關聯。這些資訊可以輕鬆地表示為表格,機器學習演算法可以從中“引導”有關與每種分析技術的增強結果,相關聯的特徵的資訊。雖然這種技術看起來很有希望,但它需要比目前可用的更廣泛的測試結果(Michie
等, 1994)。 |