|
資料來源:
Cai, L. and Zhu, Y., 2015. The Challenges of Data Quality and Data
Quality Assessment in the Big Data Era. Data Science Journal, 14, p.2.
DOI: http://doi.org/10.5334/dsj-2015-002
摘要
高品質的數據是分析和利用大數據、保證數據價值的前提條件。目前缺乏了對大數據品質標準和品質評估方法的綜合分析研究。本文首先總結了數據品質的研究。其次分析了大數據環境的數據特徵,提出了大數據面臨的品質挑戰,並從數據用戶的角度制定了層次化的數據品質框架。該框架由大數據品質維度、品質特徵和品質指標組成。最後在此框架的基礎,建立了數據品質的動態評估流程。該流程具有良好的擴展性和適應性,能夠滿足大數據品質的評估需要。研究成果通過建立評估模型和評估研究,豐富了大數據的理論範圍,為未來奠定了堅實的基礎。
一、
簡介
自 21
世紀初以來,資訊技術行業發生了許多重大的技術變革。如雲端計算、物聯網、社交網路等。這些技術發展使得數據數量不斷增加,並以前所未有的速度積累。上述所有技術都宣告了大數據的到來(Meng
& Ci, 2013)。目前,全球數據量呈指數級增長。數據單元不再是GB和TB,而是PB(1PB=210TB)、EB(1EB=210PB)、ZB(1ZB=210EB)。根據
IDC 的“數字宇宙”預測”(Gantz
& Reinsel,2012),到了2020
年將產生 40 ZB 的數據。
大數據時代的出現引起了產業界、學術界和政府的關注。例如2012
年,美國政府投資 2 億美元啟動“大數據研發計劃”(Li
& Chen, 2012)。Nature推出大數據特刊(Nature,
2008)。《Science科學》還出版了《處理數據》專刊(Science,2011),說明了大數據對科學研究的重要性。此外大數據的開發利用在醫療、零售、金融、製造、物流、電信等行業得到了廣泛應用,產生了巨大的社會價值和產業潛力(Feng等,2013)。
通過快速獲取和分析各種來源、各種用途的大數據,研究人員和決策者逐漸意識到這些海量的資訊,對於了解客戶需求、提高服務品質、預測和防範風險是有益的。但是大數據的使用和分析必須建立在準確、高品質的數據之上。這是大數據產生價值的必要條件。在此我們分析了大數據面臨的挑戰,並提出了大數據的品質評估框架和評估流程。
二、數據品質文獻綜述
1950年代,研究人員開始研究品質問題,特別是對產品的品質。以及提出一系列定義,例如品質是“一組固有特性滿足要求的程度”(
General Administration of Quality Supervision, 2008);“適用性”(Wang
& Strong, 1996);“符合要求”(Crosby,
1988 )。上述標準都已出版。後來,隨著資訊技術的飛速發展,研究轉向了數據品質的研究。
國外對數據品質的研究始於1990年代,許多學者對數據品質提出了不同的定義和品質維度的區分方法。由Richard
Y. Wang教授帶領的麻省理工大學全面數據品質管理團隊,在數據品質領域進行了深入研究。他們將“數據品質”定義為“適合使用”(Wang
& Strong, 1996),並提出數據品質判斷取決於數據消費者。同時將“數據品質維度”定義為一組數據品質屬性,代表數據品質的一個方面或結構。他們使用兩階段調查來確定包含十五個數據品質維度的四個類別。
一些文獻以網路數據作為研究對象,提出了單獨的數據品質標準和品質評估措施。Alexander
and Tate (1999)
描述了六個評估標準:權威性、準確性、客觀性、流通性、覆蓋/目標受眾,和網路數據的交互/交易特徵。Katerattanakul
和 Siau (1999)
為單個網站的資訊品質開發了四個類別和一個問卷,來測試每個新開發的資訊品質類別重要性,以及網路用戶如何確定單個網站的資訊品質。對於資訊檢索,Gauch
(2000)
提出了六個品質指標,包括流通性、可用性、信號噪音比、權威、流行度和凝聚力,用以進行調查。
Shanks and Corbitt (1999)從社會和文化的角度對數據品質進行研究,建立了4個層次共11個品質維度,基於表情的數據品質框架。Knight
和 Burn (2005)
總結最常見的維度以及它們被包含在不同數據品質/資訊品質框架中的頻率。然後,他們提出了
IQIP(識別、量化、實施和完善)模型。作為一種管理互聯網Crawling搜索引擎品質相關演算法的選擇和實施方法。
根據美國國家統計科學研究所(NISS,
2001),數據品質的原則是:
1. 數據是產品,有客戶,對他們來說既有成本又有價值;2.
作為產品,數據具有的品質,來自於數據產生的過程;3.
數據品質取決於多種因素,至少包括使用數據的目的、用戶、時間等。
中國對數據品質的研究起步晚於國外研究。2008年,第63研究所成立數據品質研究組(The
63rd Research Institute of the PLA General Staff Headquarters),討論了數據品質的基本問題,如定義、誤差來源、改進方法等(Tso
et al., 2010)。2011年,西安交通大學成立了資訊品質研究組。從流程、技術、管理等方面分析了大數據品質的保證挑戰和重要性以及應對措施(Zong
& Wu, 2013)。中國科學院計算機網路資訊中心提出了數據品質評價方法和指標體系(Data
Application Environment Construction and Service of the Chinese Academy
of Sciences, 2009),將數據品質分為外在形式品質、內容品質和品質的效用。每個類別又細分為品質特徵和評價指標。
綜上所述,現有的研究主要集中在兩個方面:1.網路數據品質的一系列研究和2.特定領域的研究,如生物學、醫學、地球物理、電信、科學數據等。在建立多源、多模態環境下的大數據品質和評估方法方面受到更多關注,但是仍然缺乏研究成果(Song
& Qin, 2007)。
三、大數據時代的數據品質挑戰
3.1 大數據的特點
由於大數據呈現出新的特徵,其數據品質也面臨許多挑戰。大數據的特徵歸結為
4V:數量、速度、多樣性和價值(Katal、Wazid
& Goudar, 2013)。體積是指龐大的數據數量。通常使用 TB
以上的數量級來衡量這個數據量。速度代表著數據正在以前所未有的速度形成,必須及時處理。多樣性表明大數據具有各種數據類型。這種多樣性將數據分為結構化數據和非結構化數據。這些多類型數據需要更高的數據處理能力。最後Value
代表低價值密度。價值密度與總數據規模成反比,大數據規模越大,數據相對價值越低。
3.2 數據品質的挑戰
由於大數據具有4V特性,企業在使用和處理大數據時,如何從海量、多變、複雜的數據集中提取高品質、真實的數據,成為一個緊迫的問題。目前大數據品質面臨以下挑戰:
1.數據源的多樣化,帶來了豐富的數據類型和復雜的數據結構,增加了數據整合的難度。
過去企業只使用自身業務系統產生的數據,如銷售、庫存數據等。但是現在企業收集和分析的數據已經超出了這個範圍。大數據來源非常廣泛,包括:
1)來自互聯網和移動互聯網的數據集(Li
& Liu, 2013);
2)來自物聯網的數據;
3)各行業收集的數據;
4)科學實驗和觀測數據(Demchenko,
Grosso & Laat, 2013),如高能量物理實驗數據、生物數據、空間觀測數據。
這些來源產生豐富的數據類型。一種數據類型是非結構化數據,例如文檔、錄影、音頻等。第二種是半結構化數據,包括:軟體套件/模塊、電子表格和財務報告。三是結構化數據。非結構化數據量佔現有數據總量的80%以上。
對於企業而言,從不同來源獲取結構複雜的大量數據,並進行有效整合是一項艱鉅的任務(McGilvray,2008)。不同來源的數據之間存在衝突和不一致或矛盾的現象。在數據量較小的情況下,可以通過手動搜索或編程,甚至通過ETL(Extract,
Transform, Load)或ELT(Extract,
Load, Transform)來檢查數據。但是,這些方法在處理PB級甚至EB級的數據數量時是沒有用的。
2.數據量巨大,很難在合理的時間內判斷數據品質。
工業革命後,以文字為主導的資訊量每十年增加一倍。1970後,資訊量每三年增加一倍。今天,全球資訊量每兩年增加一倍。2011全球數據建立和複制量達到1.8
ZB。很難在合理的時間範圍內收集、清理、整合併,以最終獲得必要的高品質數據。由於大數據中非結構化數據的比例非常高,將非結構化類型轉化為結構化類型,並進一步處理數據需要花費大量時間。這是對現有數據處理品質技術的巨大挑戰。
3.數據變化非常快,數據的“時效性”非常短,這就對處理技術提出了更高的要求。
由於大數據的快速變化,一些數據的“時效性”很短。如果企業不能即時收集所需的數據,或處理數據需要很長時間,那麼他們可能會獲得過時和無效的資訊。基於這些數據的處理和分析,會產生無用或誤導性的結論,最終導致政府或企業的決策失誤。目前大數據即時處理分析軟體仍處於開發或改進階段。真正有效的商業產品很少。
4.國內外尚未形成統一認可的數據品質標準,對大數據數據品質的研究才剛剛起步。
為了保證產品品質,提高企業效益,1987年國際標準化組織(ISO)公佈了ISO
9000標準。目前全球已有100多個國家和地區積極實施這些標準。這一實施促進了企業在國內和國際貿易中的相互了解,帶來了消除貿易壁壘的好處。相比之下,數據品質標準的研究始於
1990 年代,直到 2011 年
ISO 才發布了 ISO 8000 數據品質標準(Wang,
Li, & Wang, 2010)。目前已有20多個國家參與該標準,但是有許多爭議。標準需要成熟與完善。同時國內外對大數據品質的研究才剛剛起步,成果很少。
四、大數據的品質標準
大數據是一個新概念,學術界對其數據品質和品質標準還沒有統一的定義。各文獻對數據品質的定義各不相同。但是有一點是受到肯定的。數據品質不僅取決於其自身的特徵,還取決於使用數據的業務環境,包括業務流程和業務用戶。只有符合相關用途並滿足要求的數據,才能被認為是合格或是品質良好的數據。通常數據品質標準是從數據生產者的角度制定。過去數據消費者不是直接的,就是間接的數據生產者,從而保證了數據的品質。然而在大數據時代,隨著數據來源的多樣化,數據使用者不一定是數據生產者。因此很難衡量數據品質。在此我們從用戶的角度提出了一個分層的數據品質標準,如圖1所示。
圖 1數據品質框架。
我們選擇目前普遍接受和廣泛使用的數據品質維度,作為大數據品質標準,並根據實際業務需求重新定義其基本概念。同時每個維度又被劃分為與其相關聯的許多典型元素,每個元素都有自己對應的品質指標。通過這種方式,建立的大數據的分級品質標準被用於評估。圖2顯示了一個通用的兩層數據品質標準。表1給出了一些詳細的數據品質指標。
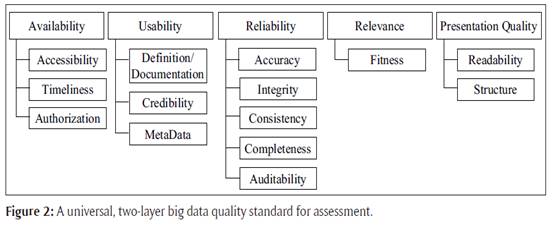
圖 2用於評估的通用、兩層大數據品質標準。
在圖2中,數據品質標準由數據品質的五個維度組成:可用性、使用性、可靠性、相關性和呈現品質。對於每個維度,我們確定了
1-5
個具有良好作業的因素。前四個品質維度被認為是數據品質不可或缺的固有特徵,最後一個維度是提高客戶滿意度的附加屬性。可用性定義為用戶獲取數據及相關資訊的便利程度,分為可存取性、授權性和及時性三個要素。使用性的概念是代表數據是否有用,並且能夠滿足用戶的需求,包括數據定義/文檔、可靠性和原數據。可靠性是指是否可以信任數據;這包括準確性、一致性、完整性、充分性和可審計性要素。相關性用於描述數據內容與用戶期望或需求之間的相關程度。適合性是其品質要素(Cappiello,
Francalanci & Pernici, 2004)。表示品質是指對數據的一種有效的描述方法,使用戶能夠充分理解數據。它的維度是可讀性和結構。下面給出了數據品質要素的描述。
可存取性
可存取性是指用戶獲取數據的難易程度。可存取性與數據開放密切相關,數據開放程度越高,獲得的數據類型越多,可存取程度越高。
及時性
及時性被定義為從數據生成和獲取到利用的時間延遲(McGivray,
2010)。數據應在此延遲內可用,以便進行有意義的分析。大數據時代,數據內容變化迅速,時效性非常重要。
授權
授權是指個人或組織是否有權使用數據。
可信度
可信度用於評估非數字數據。它指的是來源或資訊可信度的客觀和主觀成
分。數據的可信度具有三個關鍵因素:數據源的可靠性、數據規範化和數據產
生的時間。
定義/文檔
定義/文檔由數據規範組成,包括數據名稱、定義、有效值範圍、標準格式、業務規則等。規範的數據定義提高了數據的使用程度。
原數據
隨著數據源和數據類型的增加,由於數據消費者扭曲了數據的常用術語和概念的含義,使用數據可能會帶來風險。因此數據生產者需要提供描述數據集其不同方面的原數據,以減少因誤解或不一致而導致的問題。
準確性
為了確定給定數據數值的準確性,將其與已知參考值進行比較。在某些情況下,準確度可以很容易地衡量。例如性別,它只有兩個確定的值:男性和女性。但在其他情況下,沒有已知的參考值,因此很難量測準確度。由於準確性在一定程度上與上下文相關,因此數據準確性應由應用情況決定。
一致性
數據一致性是指相關數據之間的邏輯關係是否正確、完整。在數據庫領域(Silberschatz,
Korth, & Sudarshan, 2006),這通常代表著位於不同存儲區域的相同數據,應該被認為是等價的。等效是指數據具有相同的價值,和相同的含義,或本質上相同。數據同步是使數據相等的過程。
整合性
術語數據完整性的範圍很廣,根據具體情況可能具有不同的含義。在數據庫中,具有“整合性”的數據被稱為具有完整的結構。數據值根據數據模型和/或數據類型進行標準化。數據的所有特徵都必須正確,包括業務規則、關係、日期、定義等。在資訊安全中,數據完整性代表著在數據的整個生命週期內,維護和確保數據的準確性和一致性。這代表著不能以未經授權或未被檢測到的方式修改數據。
完整性
如果一個數據有多個組成部分,我們可以用完整性來描述品質。完整性代表著單個基準的所有分量的值都是有效的。例如對於圖像顏色,RGB
可以用來描述紅色、綠色和藍色,RGB
代表顏色數據的所有部分。如果某個組件的顏色值缺失,圖像就無法顯示真實的顏色,從而破壞了圖像的完整性(Wang
& Storey, 1995)。
可審計性
從審計應用的角度來看,數據生命週期包括三個階段:數據生成、數據收集和數據使用(Wang
& Zhu, 2007)。但這裡的可審計性代表著審計人員可以在數據使用階段,在合理的時間和人力限制內,公平地評估數據的準確性和完整性。
適合度
適合度有兩個層次的要求:1)用戶使用的數據量;2)產生的數據在指標定義、要素、分類等方面與用戶需求的匹配程度。
可讀性
可讀性被定義為根據已知或明確定義的術語、屬性、單位、代碼、縮寫或其他資訊,所正確解釋數據內容的能力。
結構
超過 80%
的數據是非結構化的,因此,結構是指通過技術將半結構化或
非結構化數據,轉換為結構化數據的難易程度。
五、大數據品質評估流程
為了得出有效的結論,需要一種適當的大數據品質評估方法。在本文中,提出了一種基於大數據自身特點的動態反饋機制的有效數據品質評估流程,如圖3所示。

圖 3大數據品質評估流程
確定數據收集的目標是整個評估過程的第一步。大數據用戶根據自己的策略目標或業務需求,如營運、決策、規劃等,合理選擇要使用的數據。需要提前確定數據來源、類型、數量、品質要求、評估標準和規範以及預期目標。
在不同的業務環境中,數據品質要素的選擇會有所不同。例如對於社交媒體數據,及時性和準確性是兩個重要的品質特徵。但是由於很難直接判斷準確性(Shankaranarayanan,
Ziad, & Wang, 2012),需要一些額外的資訊來判斷原始數據。其他數據來原作為補充或證據。因此信譽成為一個重要的品質維度。然而社交媒體數據通常是非結構化的,不適合評估它們的一致性和完整性。生物領域是大數據的重要來源。但是由於缺乏統一的標準,數據存儲軟體和數據格式差異很大。因此很難將一致性作為品質維度。將及時性和完整性作為數據品質維度的要求不高。
為了進一步進行品質評估,需要針對每個維度選擇具體的評估指標。這些要求數據符合特定條件或特徵。考核指標的制定還需要依據實際經營環境而定。
每個品質維度都需要不同的量測工具、技術和流程,從而導致評估時間、成本和人力資原的差異。在清楚地了解評估每個維度所需的工作之後,選擇那些滿足需求的維度可以很好地定義項目的範圍。數據品質維度的初步評估結果,確定了基線。其餘評估作為業務流程的一部分,用於持續檢測和資訊改進。
品質評估準備完成後,流程進入數據收集階段。收集數據的方式有很多種(Zhu
& Xiong, 2009),包括:數據整合、搜索下載、網路crawling、代理方法、載體監控等。在大數據時代,數據獲取相對容易。但很多收集的數據並不見得是好的。我們需要在這些條件下盡可能提高數據品質,同時又不會大幅增加獲取成本。
大數據來源非常廣泛,數據結構複雜。接收到的數據可能存在品質問題,如數據錯誤、資訊缺失、不一致、噪聲等。數據清洗(data
scrubbing)的目的是檢測和去除數據中的錯誤和不一致,以提高數據品質。數據清洗根據實現方式和範圍可分為四種模式(Wang,
Zhang, & Zhang, 2007):手動實現、編寫特殊應用程序、與特定應用領域無關的清洗數據、解決一類問題特定的應用領域。在這四種方法中,第三種方法具有很好的實用價值,可以成功應用。
然後,流程進入數據品質評估和監控階段。數據品質評估的核心是如何評估每個維度。目前的方法有兩類:定性方法和定量方法。定性評價方法是根據一定的評價標準和要求,根據評價目的和用戶需求,從定性分析的角度對數據資源進行描述和評價。定性分析應由學科專家或專業人員進行。定量方法是一種正式的、客觀的和系統的過程,其中利用數值數據來獲取資訊。因此客觀性、概括性和數量性是該方法經常關聯的特徵,其評估結果更加直觀和具體。評估後,可以將數據與上述建立的數據品質評估的基準線進行比較。如果數據品質符合基準線標準,則可以進入後續數據分析階段,並生成數據品質報告。否則,如果數據品質不能滿足基準線標準,則需要獲取新數據。
嚴格來說,數據分析和數據挖掘並不是屬於大數據品質評估的範疇。但是在數據品質評估的動態調整和反饋中發揮著重要作用。我們可以通過這兩種方法來發現大數據中是否存在有價值的資訊或知識,以及這些知識是否對政策建議、商業決策、科學發現、疾病治療等所有幫助。如果分析結果符合目標,那麼輸出結果並反饋到品質評估系統,為下一輪評估提供更好的支持。如果結果沒有達到目標,數據品質評估基線可能不合理。需要及時調整,以獲得符合目標的結果。
六、結論
大數據時代的到來,使得各行各業的數據呈現爆發式增長。如何保證大數據的品質,如何分析挖掘隱藏在大量數據背後的資訊和知識,已成為產業界和學術界面臨的重大課題。數據品質不佳會導致數據利用效率低下,甚至帶來嚴重的決策失誤。本文分析了大數據品質面臨的挑戰,提出了數據品質框架的建立和層次結構。然後制定了具有反饋機制的動態大數據品質評估流程,為進一步研究評估模型,奠定了良好的基礎。下一階段的研究將涉及建立大數據品質評估模型,並形成每個評估指標的權重係數。同時研究團隊將開發一種演算法,用於對特定領域的大數據品質進行實際評估。 |