|
資料來源:
A brief discussion of statistics and experimental design
EMBO Rep. 2012
Apr; 13(4): 291–296.
Published online 2012
Mar 16. doi: 10.1038/embor.2012.36
David L Vaux,1 Fiona
Fidler,2 and Geoff
Cumming2
摘要
可重複性樣本很重要,但它們不能用於正確檢定科學假設的有效性。
科學是通過反覆實驗或觀察獲得的知識。為了令人信服,一篇科學論文需要提供證據以證明結果是可複製的。該證據可能來自整個實驗多次獨立地重複,或者來自實驗以獲取獨立數據,並可以應用正式的統計推論程序的方式執行檢定。通常是信賴區間
(CI) 或統計顯著性檢定。在過去的幾年裡,許多期刊都加強了對作者和編輯作業的指導,以確保在圖例中誤差線(error
bars)出現在圖中。並為圖像處理軟體的使用設定標準。這有助於論文提高圖像品質。並減少只顯示誤差線但未描述它們的圖形。然而,如何描述和解釋可複製數據和獨立重複數據仍然存在問題。由於生物實驗可能很複雜,因此通常會進行複製量測來監控實驗的性能,但這種複製並不是對假設的獨立檢定,因此它們不能提供主要結果複製的證據。在這篇文章中,我們提出了我們的觀點來解釋為什麼來自可複製性的數據不能用於推斷假設的有效性,因此不應該用於計算
CI 或 P值,也不應在圖中顯示。
複製不是假設的獨立檢定,因此它們不能提供主要結果的可複製性的證據
假設我們正在檢定假設由
Bdl 基因編碼的蛋白質 Biddelonin (BDL)是骨髓菌落響應細胞因子
HH-CSF 生長所必需的假設。幸運的是,我們擁有野生型 (WT)小鼠 和純合Bdl基因缺失小鼠,以及一瓶重組
HH-CSF。我們從單個 WT 和單個Bdl-/-小鼠(來自Bdl+/-雜合雜交的同性同窩仔)製備骨髓細胞懸液,並使用血細胞計數器對細胞懸液進行計數。調整它們以使
1 × 105每毫升細胞數目於軟瓊脂生長培養基的最終溶液。我們將1 ml的懸浮液添加到
10 個 35 × 10 mm 培養皿中,每個培養皿含有
10 μl 鹽水或純化的重組小鼠 HH-CSF。
因此,我們將四組10個軟瓊脂培養基放入培養箱中:一組10個培養皿具有
WT 骨髓細胞和鹽水;第二組是Bdl-/-細胞和鹽水;第三組是帶有
HH-CSF 的 WT 細胞,第四組是帶有
HH-CSF 的Bdl-/-細胞。一週後,我們將培養皿從培養箱中取出,並使用解剖顯微鏡計算每個培養皿中的菌落數(>50
個細胞組)。菌落數目於表1。
|
|
Plate number
|
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
10 |
|
WT + saline |
0 |
0 |
0 |
1 |
1 |
0 |
0 |
0 |
0 |
0 |
|
Bdl−/− +
saline |
0 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
2 |
|
WT + HH-CSF |
61 |
59 |
55 |
64 |
57 |
69 |
63 |
51 |
61 |
61 |
|
Bdl−/− +
HH-CSF |
48 |
34 |
50 |
59 |
37 |
46 |
44 |
39 |
51 |
47 |
表
1 每培養皿的骨髓集落數
在存在或不存在
1 μM HH-CSF 的情況下,將1 × 105 WT 或Bdl-/-骨髓細胞接種在
1 ml 軟瓊脂培養基中。1 週後計數每個平培養皿的菌落數。WT為野生型。
我們可以在圖表上繪製培養皿上的菌落數量。如果我們只繪製每種類型的一個培養皿的菌落計數量(圖 1A顯示培養皿
1 的數據),很明顯 HH-CSF 為許多菌落形成的必需,但是Bdl-/-細胞與WT
細胞是否顯著不同此反應不是很明顯。此外圖表看起來不夠“科學”。沒有誤差線或P
值。此外只有顯示一個培養皿的數據,違反了科學的基本規則。即所有相關數據都應報告並進行分析,除非有充分的理由說明為什麼應該省略某些數據,不應該只提供1個數據。
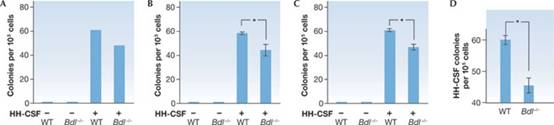
圖1
顯示複製數據—不該做什麼。(A)
僅1個培養皿的數據(如表 1所示)。(B)複製培養皿
1-3(在表 1中)的平均值 ± SE
,*P > 0.05。(C)複製培養皿
1-10(在表 1中)的平均值 ± SE
,*P < 0.0001。(D) HH-CSF
處理的複製培養皿 1-10 的平均值 ±
SE (在表 1中)。不應顯示複製的統計數據,因為它們僅表明複製結果的保持真實度,並且與正在測試的假設無關。在這些圖中的每一個中,n =
1 並且 (B)、(C)
和 (D) 中的誤差條的大小反映了複製的抽樣變化。預期複製性的
SD 大致為平均菌落數的平方根。此外軸應從 0
開始,除非在特殊情況下,例如對數刻度。SD為標準差;SE為標準誤差。
為了使它看起來更好,我們可以將每種類型的前3個培養皿中的平均菌落數添加到圖表中(圖
1B),並報告每種類型三個值的標準誤差 (SE)
的誤差線。現在它看起來更像是高度知名度期刊上的一個圖示。但是當我們使用來自每種類型的3個複製培養皿的數據來評估
WT 和Bdl-/-細胞對HH-CSF,我們發現P >
0.05,表明它們沒有顯著差異。
由於每組還有另外
7 個培養皿,我們可以繪製所有 10 個培養皿的平均值和
SE,並重新計算P值(圖 1C)。現在我們很高興地發現Bdl-/-和
WT 細胞之間存在非常顯著的差異,P < 0.0001。然而,儘管在統計有非常顯著差異,但列的高度並沒有顯著差異,而且很難看到誤差線。為了解決這個問題,我們可以簡單地將y軸座標從40而不是0開始(圖
1D),以強調HH-CSF反應的差異。儘管這樣取消了鹽水控制那組,但這些對於高知名度期刊的視覺影響並不重要。
通過少量的努力,並且沒有增加額外的實驗,我們已經將一個不起眼的結果(圖 1A,B)轉變為一個強有力支持我們的假設,即對
HH-CSF 的反應需要 BDL,具有非常顯著的P
-value,以及一個看起來可能屬於頂級期刊之一的圖形(圖 1D )。
那麼,有什麼問題呢?第一個問題是我們的數據沒有證實骨髓菌落反應了 HH-CSF生長,需要
BDL 的假設,實際上反駁了它。顯然在沒有 BDL
的情況下,骨髓集落仍然正在生長,即使數量不如完整Bdl基因時的數量多。“必需”(required)、“必要(essential)”和“強制性(obligatory)”等術語不是相等的,但在看到部分效果時仍然經常被錯誤地使用。至少我們應該重新表述我們的假設,也許是“骨髓集落形成細胞,對細胞因子
HH-CSF 的全面反應,需要 BDL”。
通過僅顯示一個培養皿的數據,我們打破了科學的基本規則,即所有相關數據都應報告並進行分析......
第二個主要問題是P和統計顯著性的計算,都是基於複製的
SE,但是在四種條件中的任何一種情況下,十種複製都是僅僅來自一隻小鼠的骨髓細胞的單一懸浮液製成。因此,我們最多可以推斷出該特定
WT 小鼠的骨髓細胞懸液,其中的集落形成細胞濃度,與該特定基因缺失小鼠的骨髓懸液之間的統計學顯著差異。我們只進行了一次比較,所以n =
1,無論我們計算多少個複製培養皿。為了做出可以通用到所有 WT 小鼠和Bdl-/-小鼠的推論,我們需要多次重複我們的實驗,使用每種類型的幾隻小鼠進行幾次獨立比較。
複製培養皿的結果不能提供獨立的數據,彼此是是相互關聯的,因為它們都來自相同的骨髓細胞懸浮液。我們在確定骨髓細胞濃度時犯了錯誤,則該錯誤的將系統地應用於所有培養皿。在這種情況下,我們通過使用血細胞計數器進行細胞計數來確定骨髓細胞的初始數量,這種方法通常只能提供
±10% 的準確度。因此無論計算了多少培養皿,或者圖 1中的誤差長條圖有多小,得出的WT和Bdl-/-細胞之間存在差異,此結論都是無效的。此外即使我們使用流式細胞儀將完全相同數量的骨髓細胞分選到每個培養皿,我們仍然只是測試了來自單個Bdl-/-小鼠的細胞,因此n仍然等於
1(參見Sidebar A中的基本原則
1 )。
Sidebar A | 統計設計的基本原則
基本原則
1
科學是通過重複實驗或觀察獲得的知識。如果n =
1,則它不是科學。因為它沒有被證明是可重複的。您需要一個獨立量測的隨機樣本。
基本原則
2
最簡單的實驗設計是一次改變一個因素,同時控制其他因素的藝術。兩個條件之間觀察到的差異只能歸因於因子 A。如果因子A這是兩個條件之間唯一不同的因素。我們總是需要考慮對觀察到的結果的合理替代解釋。圖
1中觀察到的差異可能僅反映了兩種懸浮液之間的差異,或者除了感興趣的特定基因型,是由於兩隻小鼠之間的一些或許多差異。
基本原則
3
一個結論只能適用於您從中抽取獨立量測的隨機樣本的母群。因此,如果我們對一隻小鼠的單次懸浮液進行多項量測,我們只能得出關於該特定老鼠的特定懸浮液的結論。如果我們對單個小瓶細胞因子的活性有多種量測方法,那麼我們只能將我們的結論推廣到該小瓶。
基本原則
4
儘管複製不能支持對主要實驗問題的推斷,但它們確實為實驗的進行提供了重要的品質控制。如果找到令人信服的解釋,則可以省略來自複製的異常值。儘管重複部分或全部實驗是一種更安全的策略。然而來自獨立樣本的結果只能在特殊情況下被排除在外,並且只有在有特別令人信服的理由證明這樣做是合理的情況下才能排除。
為了令人信服,一篇描述新發現的科學論文,需要提供證據證明結果是可重複的。儘管有人可能會爭辯說,即使n =
1,一隻會說話的狗也代表了一項重要的科學發現。但如果有人聲稱有一隻會說話的狗曾被觀察到會說一個字,那麼很少有人會相信。大多數人需要在多個場合,以一些獨立的觀察,看到狗說幾句話。多莉羊的克隆代表了一項科學突破,但她只是Campbell等(1)描述的五隻克隆羊之一[ 1 ]。通過微細胞分析對八隻胎兒和綿羊進行了分型,結果顯示它們與用於提供供體細胞核的細胞系相同。
只能對從抽取的獨立樣本對於母群進行推斷。在我們最初的實驗中,我們從骨髓細胞的懸浮液中提取了一個體的可重複性等分試樣(圖
2A)。因此我們只能將我們的結論推廣到我們等分試樣來自的“母群”。在這種情況下,母群是骨髓細胞的特定懸浮液。為了檢定我們的假設,有必要進行類似於圖
2B所示的實驗。在這裡,骨髓已從 WT 小鼠的隨機樣本和另一個Bdl-/-小鼠隨機樣本中獨立分離。在這種情況下,我們可以得出關於Bdl-/-小鼠的通用結論,並將它們與
WT 小鼠(通用)進行比較。在圖 2A中,與
WT 小鼠(這是與我們的假設相關的比較)進行比較的Bdl-/-小鼠的數量為
1,無論計算了多少可複製培養皿因此n = 1。相反,在圖
2B中,我們將三隻Bdl-/-小鼠與三隻WT對照進行比較,因此n =
3,無論我們對每種類型的三個複製培養皿還是 30
個培養皿進行試驗。但是請注意,出於統計原因,非常希望樣本大於n = 3,和/或是增加通過其他方法檢定假設,例如,通過使用阻斷
HH-CSF 或 BDL 的抗體,或通過在Bdl-/-細胞中重新表達Bdl cDNA (參見基礎Sidebar
A中的原則 2 )。
圖
2
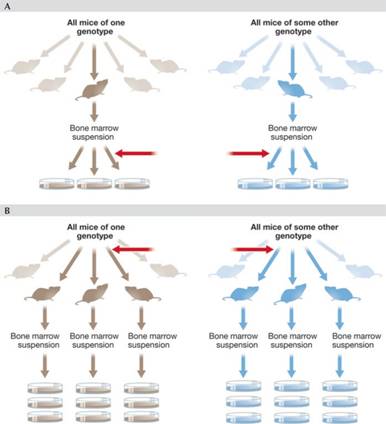
樣本變異。樣本之間的差異可用於推斷從母群中抽取獨立樣本的母群(紅色箭頭)。為了複製,如 (A)
中所示,只能對從中取出等分試樣的骨髓懸浮液進行推斷。在 (A)
中,我們或許可以推斷出左右培養皿上的細胞來自不同的懸浮液,並且骨髓細胞可能來自兩隻不同的小鼠,但我們無法就推論不同基因型的小鼠是否有影響。在(B)中,從每個基因型中選擇了三隻獨立的小鼠,因此我們可以推斷出基因型的所有小鼠。請注意,在
(B) 中的實驗中,無論建立了多少複製培養皿,n = 3。
確定
mRNA 程度的最常用方法之一是即時定量逆轉錄 PCR(qRT-PCR;儘管以下例子同樣可以適用於
ELISA 或類似方法)。通常,使用多孔培養皿,以便可以在 PCR
機器中同時讀取許多樣品。假設我們使用 qRT-PCR
來比較對照骨髓細胞(僅用培養基處理)中的Boojum mRNA (Bjm) 水準和用
HH-CSF 處理的骨髓細胞中的Bjm水準,以檢定假設HH-CSF是否表達誘導Bjm基因。
我們從一隻正常小鼠中分離出骨髓細胞,並將含有一百萬個細胞試樣的相同等分,分配到六孔培養皿的兩個孔中。目前我們只使用六孔中的兩孔。然後,我們將
4 ml 普通培養基添加到其中一個孔(對照孔)中,並將 4 ml有補充HH-CSF
的培養基混合物添加到另一個孔(實驗孔)中。我們將培養皿培育24小時,然後將細胞轉移到兩個試管中。在其中我們使用
TRizol 提取 RNA。然後我們將
RNA 懸浮在 50 μl TRIS無
RNAse 水的緩衝液。
我們將每一管中的
10 μl 放入兩個新試管,以便可以在每個樣本中確定Actin(作為對照)和Bjm資訊。我們現在有四管,每管裝有
10 μl mRNA 溶液。我們製作了兩組“反應混合物”。唯一的區別是一組包含肌動蛋白PCR
引物和其他Bjm引物。我們向四個試管添加40
μl 一種或另一種“反應混合物”,因此現在每個試管中有50
μl。混合後,我們從四個試管中的每個試管中取出三個 10 μl
的等分試液,並將它們放入 384 孔培養皿的三個孔中,這樣總共有12
個孔包含 RT-PCR
混合物。然後我們將培養皿放入熱循環儀。一個小時後,我們得到一個結果的 Excel 電子表格。
我們應該完全放棄複製嗎?答案當然是不'。複製可作為實驗進行的內部的品質檢查
然後,我們計算Bim信號與Actin信號與Actim信號之比例。其中3相對反應來自
HH-CSF 處理的細胞的 RNA。以及三對對照反應。在這種情況下,三個複製中的變化將不被取樣誤差的影響。大多數的變化在早期骨髓細胞集落形成實驗的菌落數時影響,但將僅是反應的保真度與複製,或許在PCR機器的單獨的孔的加熱有一些變化。三個
10 μl 等分試樣均來自相同的單一 mRNA
製劑,因此我們只能推斷該特定試管的內容物。與前面的例子一樣,在這種情況下,n仍然等於
1。並且不能對主要的實驗假設做出推論。如果對於 10 或
100 個孔中分析每個 RNA
樣本,情況也是如此。我們只是將一個對照樣本與一個實驗樣本進行比較,因此n = 1(圖
3A)。為了得出關於 HH-CSF 對Bjm表達影響的推論,我們必須對源自
HH-CSF 刺激的骨髓細胞,其獨立培養基的幾個獨立樣本進行實驗(圖 3B)。
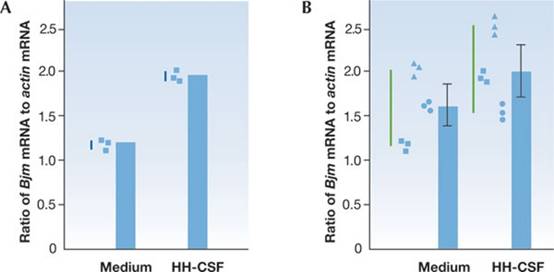 圖
3 圖
3
與獨立樣本平均值相比的複製平均值。(A)
顯示了來自一種 HH-CSF 刺激細胞培養基和一種未刺激細胞培養基。其六等分
RNA的三複製Bjm PCR 反應與三複製肌動蛋白PCR
反應的比例(實心方塊)。比例的平均值顯示為列。三個複製值(藍線)的密切相關性表明複製具有高保真度並且產生移液是一致的,但與正在測試的假設無關。因為n =
1,此處不適合顯示P 值。(B)使用來自其他培養基的
mRNA(兩個未刺激,兩個用 HH-CSF 處理)的複製PCR
反應的比例顯示為三角形和圓圈. 請注意複製(即三個形狀的組)之間的相關性遠大於三個獨立的未處理培養基和三個獨立的
HH-CSF 處理培養基(綠線)的平均值之間的相關性。誤差條表示來自三種獨立培養的比例的SE,而不是任何單一培養的複製。P >
0.05。SE,標準誤差。
例如,我們可以將骨髓細胞放入組織培養培養皿的所有六個孔中,並在沒有 HH-CSF
的培養基中,進行 3 次獨立培養。並且在培養基中進行
3 次獨立對照培養。然後可以從六種培養基中提取 mRNA,並將每個培養基分成六個孔,以使用
qRT-PCR量測肌動蛋白和Bjm mRNA 水準。在這種情況下,機器將讀取
36 個孔。如果以這種方式進行實驗,則n = 3。因為存在三種獨立的對照培養基和三種獨立的
HH-CSF 依賴性培養基,它們正在檢定我們的假設,即 HH-CSF 是否誘導Bjm表達。然後,我們可能能夠概括我們關於那瓶重組
HH-CSF 對Bjm mRNA影響結論。然而在這種情況下(圖
3B)P > 0.05,因此我們不能排除觀察到的差異僅僅是偶然的可能性,並且
HH-CSF 對Bjm mRNA
表達可能沒有影響。請注意我們也不能斷定它沒有效果。如果P > 0.05,我們唯一能得出的結論就是我們不能得出任何結論。如果我們在圖
3A中計算並顯示了重複性的誤差和 P
值,我們可能得出錯誤的結論,並可能誤導讀者得出結論,即 HH-CSF 在刺激Bjm轉錄方面具有統計學意義(參見基本原則
3Sidebar A)。
為什麼要為複製而煩惱呢?在前面的部分中,我們已經看到複製不允許做出推論,或者允許我們得出與我們正在測試假設相關的結論。那麼我們應該完全放棄複製嗎?答案當然是不'。複製可作為對實驗如何進行的內部品質檢查。例如如果在表
1和圖 1中描述的實驗中,用鹽水處理的
WT 骨髓的複製培養皿之一包含 100
個菌落,您會立即懷疑有什麼問題。您可以檢查盤子是否貼錯標籤。您可能會使用顯微鏡觀察菌落,發現它們實際上正在污染酵母菌落。如果您沒有進行任何複製,您可能不會意識到發生了錯誤。
複製
[…] 不能用於推斷結論
圖
4顯示了與圖 3相同的 qRT-PCR
實驗的結果。但在這種情況下,對於一式三份 PCR
比例中的一組,其變化比其他組大得多。此外這種大的變化可以由三個複製中的一個值來解釋。即圖中最上面的圓圈。如果您有圖
4A中的結果,您將查看肌動蛋白PCR 和Bjm PCR
的各個數值,以了解具有奇怪結果的複製數據。如果Bjm PCR
樣本異常高,您可以檢查 PCR
培養皿中相應的孔,看它是否與其他孔有相同體積。相反,如果肌動蛋白PCR
值遠低於其他兩個複製的值,則在檢查培養皿中的孔時,您可能會發現體積太低。或者,異常結果可能是由於意外添加了兩份
RNA 或兩份 PCR
引物反應混合物。或者可能是移液器吸頭鬆了。或者有晶體遮擋了光學元件,或者移液器被一些碎屑等堵塞了等等。因此,複製可以提醒您異常結果,以便您知道何時查看進一步以及何時重複實驗。複製可以作為對實驗進行的保真度的內部檢查。他們可以提醒您有關管道、洩漏、光學、污染、懸浮、混合或混淆的問題。但它們不能用於推斷結論。
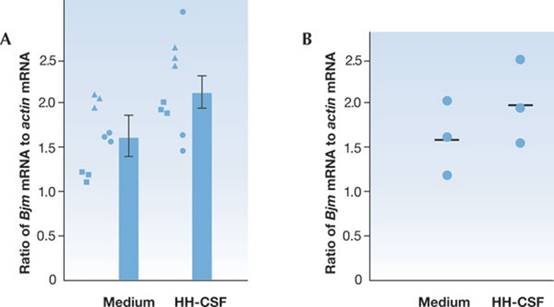 圖
4 圖
4
從複製解釋數據。(A)
三個獨立培養基的平均值 ± SE,每個培養基的比例來自三次
PCR 量測。P > 0.05。該實驗與圖
3B中的實驗非常相似。但是請注意,在這種情況下,對於一組複製(來自 HH-CSF
處理的複製值之一的圓圈),與其他五組一式三份的值相比,範圍要大得多。因為複製經過精心設計,盡可能地相互相似。所以發現意外的變化,應該促使調查在實驗過程中出了什麼問題。請注意在這種情況下,一組複製之間變化的增加如何導致獨立
HH-CSF 結果值的 SE 降低。圖
4A中 HH-CSF 條件的 SE直方圖,比圖
3B中的短. 未能注意複製的異常變化可能導致不正確的統計推斷。(B)三種獨立培養基的Bjm mRNA
水準(相對於肌動蛋白),每種培養基的比例來自三次 PCR
量測。平均值用水平線表示。此處數據與圖 3B或圖 4A的數據相同,但刪除了異常值。當n小到
3 時,最好只繪製數據點,而不是顯示統計數據。SE為標準誤差。
因為複製值與被檢定的假設無關,它們以及從它們得出的統計數據不應在圖中顯示。在圖 4B中,大點表示在圖
4A中排除異常複製值之後的複製值的平均值。雖然在此圖中,您可以繪製來自三個獨立的培養基和
HH-CSF 處理的培養基的 mRNA 結果的平均值和
SE,但在這種情況下,繪製了獨立值,並且沒有顯示誤差線。當獨立數據點的數量很少,並且在圖表上繪製時很容易看到時,我們建議簡單地這樣做,直接顯示數據,而不是顯示平均值和誤差線。
我們在閱讀論文時應該注意什麼?儘管複製可以成為監控實驗性能的有價值的內部控制,但在出版物的圖示中顯示它們是沒有意義的。因為來自複製的統計數據與正在測試的假設無關。事實上,如果顯示了統計數據、誤差線和複製的
P
值,它們可能會誤導論文的讀者,他們會認為它們與論文的結論相關。這樣做的必然結果是:如果您正在閱讀一篇論文,並看到其中的誤差線(無論是標準偏差、SE
還是 CI)異常小,它可能會提醒您它們來自複製而不是獨立樣本。您應該仔細檢查圖例,以確定統計數據是來自複製還是獨立實驗。如果圖例沒有說明誤差線是什麼,n是什麼,或者結果是否來自複製或獨立樣本,請問問自己,這些遺漏點是否會破壞論文的結果,或者是否仍然可以從閱讀中獲得一些知識。
如果顯示了統計數據、誤差線和複製值的
P 值,它們可能會誤導論文的讀者,他們認為它們與論文的結論相關
如果該圖僅包含來自具有複製統計的單個實驗的數據,您也應該持懷疑態度,因為在這種情況下,n = 1,並且無法得出有效的結論。即使作者聲明結果具有“代表性”-如果作者有更多數據,他們應該將它們包含在已發布的結果中(請參閱Sidebar
B了解要查找的內容的清單)。如果您想查看更多在論文報導上不該做什麼的例子,請在互聯網上搜索短語“
SD”、“ SE”、“SEM”、“複製的
SD”或“複製的 SEM” '。
Sidebar B | 閱讀論文時的錯誤檢查清單
1.如果顯示誤差線,它們是否在圖例中描述?
2.如果顯示統計數據或誤差線,是否說明了n值 ?
3.如果標準偏差
(SD) 小於 10%,結果是否來自複製?
4.如果二項式分佈的
SD 始終小於 √(np(1 – p))(其中n是樣本量,P是概率),數據是否好得令人難以相信?
5.如果卜瓦松分佈的
SD 始終小於 √(平均值),那麼數據是否好得令人難以相信?
6.如果統計數據來自複製,或來自單個“代表性”實驗,請考慮這些實驗是否為結論提供了強有力的支持。
7.如果為複製或單個“代表性”實驗顯示
P 值,請考慮這些實驗是否為結論提供強有力的支持。 |



