|
資料來源:
https://www.projectpro.io/article/types-of-regression-analysis-in-machine-learning/410
迴歸分析是數據科學和機器學習從業者的最喜愛的技術,因為它提供了高度的靈活性和可靠性,使其成為分析不同情況的理想選擇,例如:
1.學歷和智商會影響薪水嗎?
2.咖啡因和吸煙與死亡風險有關嗎?
3.定期鍛煉和飲食計劃會影響體重嗎?
4.構建多元線性迴歸模型的時間序列項目
什麼是迴歸分析?
根據維基百科,迴歸分析被定義為一組統計過程,用於估計應變數和一個或多個自變數之間的關係。
沒有多大意義,是嗎?
讓我們試著用一個實例以理解迴歸分析。想像一下,你和朋友做了很久的計劃,你想出去,但你不確定是否會下雨。現在是季風季節。但是你媽媽說今天空氣很乾燥,所以下雨的可能性較小。相反地你姐姐認為,因為昨天下雨,今天很可能會下雨。你不是雷電之王,你無法控制天氣,你將如何決定要更認真地對待誰的意見,同時記住你對兩者都要公正的事實?
迴歸分析可能會為您提供幫助。降雨取決於許多因素,例如地理位置、一年中的時間、降水量、風速,但除非您是氣象部門或
Sheldon,否則您不會想要使用所有這些數值。
因此,您將根據濕度水準和前一天的降水量來決定今天的降水量水準或降雨量。您可以在網路上輕鬆獲取這兩個值,我知道您也可以獲取今天的天氣預報,但我們正在嘗試在這裡學習一些東西。
在我們的例子中,我們試圖預測的是今天的降水量,它由昨天收到的濕度和降雨量所決定,因此它被稱為應變數。它所依賴的變數將被稱為自變數。我們對迴歸分析所做的工作,是對這兩種變數之間的關係進行建模或量化,從而在一定程度上以另一種變數的幫助下進行預測。有根據的猜測比隨機猜測要好。為了解決我們的問題,我們要做一個簡單的線性迴歸,我們將收集上個月的濕度水準和降水水準並繪製它們。
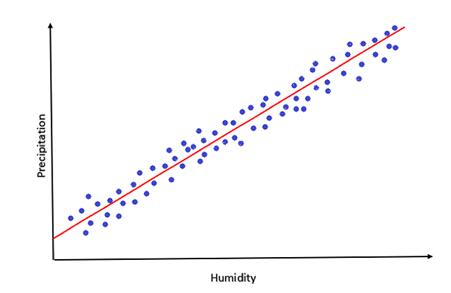
即使不做任何數學運算,我們也可以推斷濕度和降雨(降水)是線性相關的。一個數值的增加也會導致另一個數值的增加。但是在這裡,可以看到我們通過很多假設來過度簡化問題。主要的假設是濕度是決定降雨的唯一或最重要的因素。在現實世界不是那麼簡化,業務問題中有許多變數之間存在復雜的關係。為了處理所有這些複雜性,有幾種不同類型的迴歸分析方法,我們將在本文中加以介紹:
迴歸分析:了解相關術語
異常值:異常值基本上是與一般母群或數據分佈非常偏離的數值或數據點。異常值能夠使任何 ML
模型的結果偏向於它們的檢定結果。因此有必要及早發現它們或使用抗異常值的演算法。
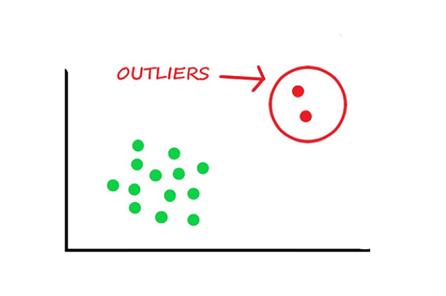
圖片來源:https://datascience.foundation/
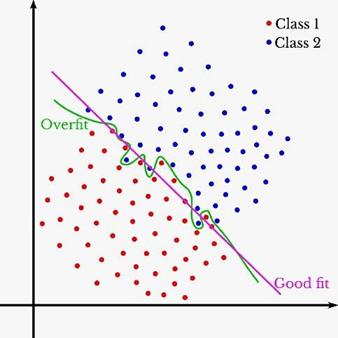
過度適配:當 ML
模型學習訓練數據時會發生過度適配,這樣它就可以記住每一個小細節和噪音,從而使其通用性降低。因此該模型在任何未知數據集上的表現都很糟糕,並且非常複雜。
圖片來源:https://towardsdatascience.com/
異質變異量性:這個術語甚至很難閱讀,更不用說理解。所以舉個例子。我們預測降雨或降水的濕度。現在隨著濕度的增加,降水增加或減少的量是可變的,而不是固定的。
機器學習中的 18 種迴歸分析
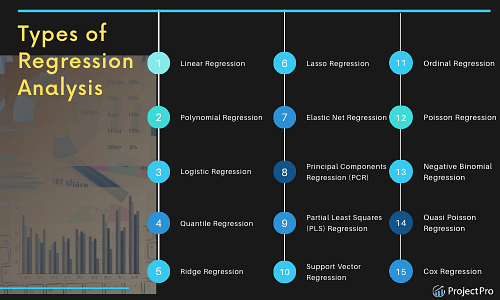
(1)線性迴歸分析:
上述的迴歸類型是線性迴歸。假設我們的預測變數和解釋變數之間存在線性關係。線性迴歸將嘗試通過將線性方程適配到觀察數據來模擬兩個變數之間的關係。在我們的例子中,y
是降水量,X 是濕度,而a 和b 是迴歸係數。對於所有觀察到的點 y、X,我們嘗試找到最適合我們方程式的a 和b
值。在稍微複雜的情況下,還會有很多變數影響降雨,如溫度、一年中的哪一天、前一天的降水量等。對於這種情況有多個自變數,我們有多元線性迴歸和方程式。它是這樣的:
y = a + bX1 + cX2
+ dX3 ……。
其中X1、X2、X3
均為解釋變數,a、b、c 為迴歸係數。正係數表示預測變數對應變數的積極影響有多大,負係數表示反之亦然。
線性迴歸分析的好處和應用
儘管簡單,線性迴歸是一種非常強大的技術,可用於產生有關消費者行為、了解業務和影響盈利能力的因素的見解。它可以在商業中用於評估趨勢並做出估計或預測。
線性迴歸還可以通過數據驅動決策來提高業務的營運效率。自行車租賃公司可以通過對租賃的自行車數量與一天中的時間、道路上的交通、天氣等因素之間的關係進行建模,來避免自行車庫存過多或庫存不足。
線性迴歸分析的局限性和假設
線性迴歸假設應變數和自變數之間存在線性關係,這在現實世界中通常不是這種情況。這時要使用其他解釋非線性的迴歸技術。
如果自變數彼此相關,換句話說,如果存在多重共線性,線性迴歸也不會做得很好。為了避免這種情況,只保留一個相關的自變數。
它還假設不同的觀察是相互獨立的。今天的降雨量與昨天的降雨量無關。往往不是一個非常現實的假設。
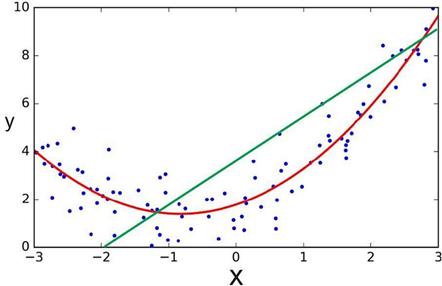
(2)多項式迴歸分析
多項式迴歸的需求源於對非線性的應變數和自變數之間的關係需要進行建模。這在大多數實際應用中通常是這種情況。多項式迴歸的方程式顯然是一個多項式:
y = a + bX + cX2 + dX3
……
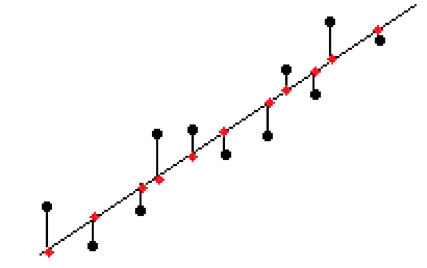
讓我介紹一個稱為損失函數的概念,用於評估迴歸演算法的有用性。在將我們的迴歸線適配到我們的數據時,我們以這樣一種方式定位,即數據點與線的垂直距離之和最小化。
均方根誤差與此非常相似,它只取這些殘差的平方(其一點到直線的距離)並取它們總和的平方根。這裡Predictedi是紅點, Actualiare是黑點。
RMSE 將告訴您迴歸線的適配程度。
當變數之間的關係不是線性的時。而且很難在數據上適配一條線以最小化我們的成本函數。這是我們需要多項式迴歸的時候。
多項式迴歸分析的好處和應用
除了提供變數之間的最佳近似水準,多項式迴歸還提供了範圍廣泛的函數。在工業中,多項式迴歸可用於所有使用線性迴歸但需要可靠性更高的情況,因為我們沒有違反線性假設。
多項式迴歸分析的局限性和假設
為線性迴歸所做的大多數假設在這裡仍然有效。假設數據不是多重共線性的,獨立於後續觀察,並且沒有異質變異性。
多項式迴歸對異常值的存在也很敏感。使用演算法檢測異常值也很困難,它們的存在會使結果向它們的方向傾斜。
(3)邏輯迴歸分析
上述兩種方法的一個共同特點是應變數是連續的。在邏輯迴歸中,應變數是離散的(或分類的),而自變數可以是離散的或連續的。它以對數函數的核心函數命名。方程式是這樣的:
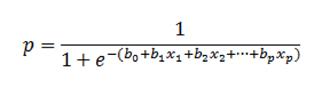
其中 x1, x2 , x3是自變數,b0, b1, b2
是迴歸係數。在二元分類問題中,p 給出了樣本屬於主類的概率。
當邏輯迴歸應用於現實世界的問題時,比如在這裡檢測人的癌症,P為判斷這個人是否患有癌症的概率。 P 小於 0.5 表示沒有癌症,大於 0.5
表示有癌症。邏輯迴歸是一種線性方法。但預測值是使用邏輯函數轉換的。它的曲線遵循對數函數的曲線。
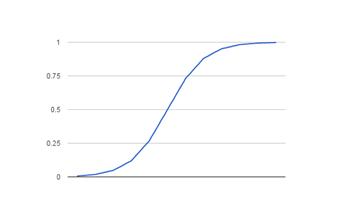
邏輯迴歸分析的好處和應用
邏輯迴歸是目前使用最廣泛的演算法之一。它易於實施且用途廣泛。從花瓣識別到文本分類,它被用於一些最複雜的深度學習架構的頂部,作為分類層
。
它可以與各種輸出類一起使用,它還輸出與類關聯的大小。它還可以將模型係數解釋為特徵重要性的指標。
與 SVM 等其他分類演算法不同,它的訓練速度相對較快。
邏輯迴歸分析的局限性和假設
邏輯迴歸是線性演算法的核心。因此,它遵循線性迴歸的大多數假設,例如輸入變數和輸出變數之間的線性關係、自相關等。
如果觀察數目少於自變數目,則邏輯迴歸可能會過度適配。它對數據中的異常值和噪聲也很敏感。
(4)分位數迴歸分析
在概率分佈中,分位數是將分佈範圍劃分為具有相等概率的連續區間的點。對於常態分佈,分位數將按如下方式放置:
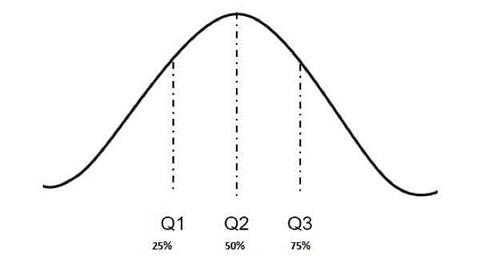
在我們的概率分佈中,25% 的數據點位於 Q1 的左側,75% 的數據點位於
Q3 的左側。
普通最小二乘迴歸或線性迴歸是圍繞應變數的平均值建模的。分位數迴歸使我們能夠理解數據平均值之外的變數之間的關係,從而有助於理解非常態分佈的結果以及與預測變數具有非線性關係的結果。
ð – th分位數的方程式由下式給出
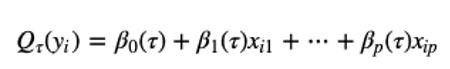
其中ð –可以是第一個、第二個或第三個分位數。 p是應變數的數量,所有的 β
都是我們建模的迴歸係數。
分位數迴歸分析的好處和應用
線性迴歸的假設當不滿足時,可以使用分位數迴歸。它對異常值具有強韌性,存在異質變異量時也可以使用。
當數據偏斜時,它也很有用,因為它不依賴於平均值的度量值而是依賴分位數。在任何企業中,客戶花費的金額都可能存在偏差,企業可能對最高分位數而不是平均值更感興趣。
分位數迴歸分析的局限性和假設
如果線性迴歸模型的所有假設都滿足,則使用分位數迴歸的效率低於其他替代方法。
與邏輯迴歸不同,分位數迴歸適用於預測連續變數,並且由於它對分位數進行預測,因此準確度較低。
(5) 序數迴歸分析
當應變數是有序的時,使用此技術。序數變數是分類變數,但類別按
Low、Moderate、 High等排序/排名。序數迴歸可以看作是處理迴歸和分類之間的中間問題。序數迴歸的公式來自一種稱為廣義線性模型的技術,如下所示:
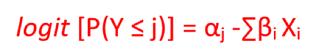
序數迴歸分析的好處和應用
序數迴歸經常出現在社會科學,例如在人類偏好水準的建模(例如,從“非常差”到“優秀”的等級為
1-5)。以及在資訊檢索中。它是預測多類有序變數的最佳技術。
序數迴歸分析的局限性和假設
平行線假設:除最後一個類別外,每個類別都有一個迴歸方程式。最後一個類別概率可以預測為最後一個1-second類別概率。
估計值有時是不可信的,這表明數據分佈太薄弱,需要使用其他方法。
(6)支持向量迴歸
在進一步討論之前,先解釋一下支持向量機(SVM)的概念。讓以具有
2 個特徵(自變數)和2個分類的 2D 數據集為例。我們可以很容易地將它們繪製成二維空間。
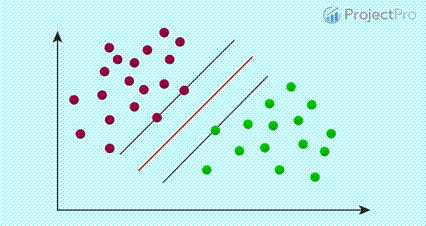
紅點對應一類,綠點對應另一類。這些類別可以很容易地在 2D
空間中用一條線分開。但是對於SVM
,它不能只是任何一行。取兩個類中最接近的點之間的距離,從中途通過的線稱為是最佳分割平面。這些在決定分隔線位置方面發生主要作用的點稱為支持向量。因此整個技術稱為支持向量機。在更現實的情況下,我們有一個
n 維空間,其中有n個特徵數量,決策平面顯然不是線性的。
在支持向量迴歸中,我們有一個連續的應變數而不是離散的應變數,並且沒有決策邊界,我們有一條迴歸線來適配我們的數據。現在找到最佳適配線或平面的方式與上面所做敘述有點不同。為了簡化,考慮一個
2D 平面。
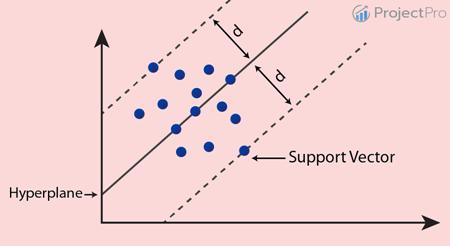
這些點分佈在二維空間中。現在採用彼此最遠的兩個點,換句話說,它們之間的最大距離是支持向量通過該垂直距離中值的線是我們的最佳適配線。
支持向量迴歸分析的好處和應用
雖然對異常值具有強韌性,但 SVR
在高維空間中的效果比線性迴歸模型要好得多。您可以定義信賴區間或容許水準。在訓練時用 C
標記。通過量測分類的信賴度來提高預測準確度。這在不需要非常精確的預測,但需要信賴區間之間的預測的實際系統中很有用。在支持向量迴歸分析中容納新數據點非常容易。
支持向量迴歸分析的局限性和假設
它們需要大量時間來訓練,不適合更大的數據集。如果樣本數量少於特徵數量,SVR
將嚴重表現不佳。這些預測沒有概率解釋。
(7)卜瓦松迴歸分析
卜瓦松分佈是一個離散概率分佈,它涵蓋了在一段時間內發生的事件數量,給定事件在該時間段內發生的平均次數。當應變數遵循卜瓦松分佈或基於計數時,我們使用卜瓦松迴歸。基於計數的數據包含以特定速率發生的事件。發生率可能會隨著時間或從一個觀察到下一個觀察而改變。我們上面提到的例子就是一個例子。卜瓦松分佈的公式遵循這個概率質量函數:
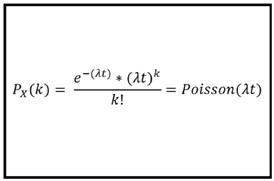
其中PX( k) 是在時間 t 內發生看到 k
個事件的概率,e-(λt)是事件機率或每單位時間發生的事件數,k 是事件數。
考慮一家小型餐廳,我們正在記錄上午 10 點到 11
點之間一小時內,步行的顧客數量,此時餐廳內平均有 5 位顧客。有了這些資訊,我們可以計算上午 10 點到 11 點之間沒有客戶的概率如下:

圖片來源:https://towardsdatascience.com/
卜瓦松迴歸分析的好處和應用
許多企業依賴基於計數的數據,例如一小時內租用的自行車數量,呼叫中心在一天中特定時間接到的電話數量。或者在一個月中特定時間訂購的披薩數量。當數據傾斜和稀疏時,它很有用。它用於確定事件在指定時間範圍內,可能發生的最大和最小次數。
卜瓦松分析的局限性和假
卜瓦松迴歸的假設是應變數必須是基於計數的,觀察必須獨立於另一個,並且卜瓦松隨機變數的平均值必須等於其變異量。在條件變異量大於條件平均值的情況下,卜瓦松迴歸可能表現不佳,這種現象稱為過度離散。
(8)負二項式迴歸:
與卜瓦松迴歸一樣,負二項式迴歸也適用於計數數據。在某種程度上,負二項式迴歸優於卜瓦松分佈,因為它的平均值不必等於變異量。現實世界的數據通常不滿足這種嚴格的假設(平均值=變異量)。在現實世界的數據中,變異量不是大於稱為過度離散的平均值,就是小於稱為欠離散的平均值。

與卜瓦松分佈幾乎相同。負二項式迴歸可以被認為是卜瓦松迴歸的推廣,因為它與卜瓦松迴歸具有相同的平均值結構,並且它有一個額外的參數來模擬過度分散。
負二項式迴歸分析的優點和應用
一個用例是學校管理人員研究兩所學校高中生的出勤行為。缺勤天數的預測因素包括學生註冊的課程類型,以及他/她在數學標準化考試中的表現。
它比卜瓦松迴歸具有明顯的優勢,因為它不必使平均值等於變異量假設。
負二項式迴歸分析的局限性和假設
1.當樣本數量較少時,負二項式迴歸可能不是一個好的選擇。
2.結果變數不能有負數。
3.自信地構建端到端項目。
(9)主成分迴歸:
這種迴歸技術基於主成分分析。在 PCR
中,不是直接對解釋變數的應變數進行迴歸,而是使用解釋變數的主成分作為迴歸量。先看看什麼是 PCA 。 PCA
基本上是一種降維方法,用於在不損失大部分資訊的情況下,降低大型數據集的維度(特徵數量)。為了簡單而犧牲了一點準確性。
這是將點從 2D 轉換為 1D 空間的例子。

在 PCR 中,遵循的步驟如下:
對解釋變數執行 PCA
以獲得主成分,然後從中選擇一個子集。使用這個子集和我們的應變數,適配成為線性迴歸模型,以獲得估計迴歸係數的向量。再將此向量轉換回原始自變數的尺度。
主成分迴歸分析的好處和應用
PCR 的最大優勢之一是可以對原始數據進行一致性檢查,而 MLR 則沒有。
PCR 也不太容易過度適配。
即使解釋變數相關,也可以使用 PCR。當特徵值多於觀測值時,也可以運行它。
主成分迴歸分析的局限性和假設
在決定刪除哪些主成分時,不考慮應變數。丟棄組件的決定僅基於組件的變異量大小。
在 PCA 中,數據未標準化,因此對特徵的規模很敏感。改變尺度會完全改變 PCA
的結果。
(10) 偏最小二乘迴歸
它是主成分迴歸的擴展。它不是在應變數和自變數之間,找到最大變異量的超平面,而是將預測變數和可觀察變數投影到新空間來找到線性迴歸模型。
這兩種變數都映射到一個新的空間,因此它克服了 PCA 的限制。 PLS
迴歸模型將嘗試在 X 空間中找到解釋Y空間中,最大多維變異量方向的多維方向。數學模型由下公式給出:

其中X是自變數矩陣,Y是應變數矩陣; T 和 U 矩陣分別是X,Y,P 和 Q
的投影,分別是正交加載矩陣;矩陣
E 和 F 是誤差項,它們是獨立同分佈的隨機常態變數。 X 和 Y 的分解是為了最大化 T 和 U 之間的共變異量(covariance)。
偏最小二乘迴歸的好處和應用
PLS 可用於異常值的檢測。與 PCR
一樣,它也可以處理比觀察更多的特徵。它還提供了更高的預測準確性和更低的偶然發現相關性的風險。它與 PCR 具有大部分相同的優點。
偏最小二乘迴歸的限制和假設
主要限制是過度忽略真實相關性,和對描述(獨立)變數的相對縮放的敏感性,有更高的風險。
該技術再次對縮放(scaling)敏感。
(11)Tobit迴歸分析
在 Tobit
迴歸中,應變數的觀察或已知範圍以某種方式被審查。在統計學中,審查(censor)是一種變數值僅有部分已知的情況。審查或剪輯(clipping)可以通過以下方式發生-當數值等於或高於某個臨界值的情況下,從上方進行審查,數值全部採用該臨界值,以便真實值可能等於臨界值,但它也可能更高。在從下方進行審查的情況下,將審查那些落在或低於某個臨界值的值。
讓我們看一個Tobit分析的例子:
一個研究項目正在研究家庭飲用水中的鉛含量與房屋年齡和家庭收入的關係。水測試套件無法檢測到鉛濃度低於十億分之五 (ppb)之數值。 EPA
認為高於 15 ppb 的水準是危險的。這些數據是左刪失(從下方刪失)的例子。
Tobit迴歸分析的好處和應用
Tobit 的方法可以很容易地擴展到處理截斷和其他非隨機選擇的樣本。 Tobit
模型已應用於需求分析,以適應對某些商品零支出的觀察。
它還被應用於估計影響撥款接收的因素,包括分配給可能申請這些撥款的地方政府的財政轉移。在這些情況下,贈款接受者不能收到負數,因此數據會被左審查。
Tobit迴歸分析的局限性和假設
Tobit 模型的一個限制,是它假設兩種結果狀態下的過程都等於一個比例常數。
如果您有一個基本有界的應變數,而不是截斷的應變數,您可能希望轉移到一個廣義線性模型框架,該框架具有對Y值的一種分佈,例如對數常態、伽馬、指數等。
(12) Cox迴歸分析
Cox
迴歸模型常用於醫學研究,用於研究患者生存時間與一個或多個預測變數(生存時間所依賴的數值)之間的關聯。該模型的目的是同時評估幾個因素對生存的影響。換句話說它使我們能夠檢查特定因素,如何影響特定事件在特定時間點發生(例如,感染、死亡)的速率。這個比率通常被稱為危險率。在生存分析文獻中,預測變數(或因子)通常被稱為共變數。
Cox 模型由h( t) 表示的風險函數表示。簡而言之,風險函數可以解釋為在時間 t 死亡的風險。可以估計如下:

t代表生存時間,h(t) 是風險函數,係數 b1, b2,...等衡量共變數
x1, x2, ... xp的影響。h0 是基線風險。
Cox 迴歸分析的優點和應用
它可用於調查飲食、運動量、睡眠時間、年齡等因子對一個人被診斷患有癌症等疾病後的生存時間的影響。生存數據通常具有審查數據,並且分佈高度偏斜。由於這兩個問題,不能使用多重迴歸。它使用多變數方法,可以解釋每個變數對結果的影響。
Cox迴歸分析的局限性和應用
如果不滿足風險假設的比例性,則迴歸結果不正確。該模型還假設每個共變數在風險函數中具有隨時間不變的乘法效應。
(13)脊迴歸分析
在進一步討論之前,讓我們了解正規化的概念。正規化是一種用於處理過度適配的技術。它在損失函數中增加了一個額外的誤差項,以懲罰過度適配並且促進通用。因此,除了針對損失最佳化模型係數之外,我們還針對正規化項進行了最佳優化,因此我們得到了一個適配良好的模型。基本上有兩種正規化——L1和L2。我們將通過使用它們的迴歸模型來更好地理解它們。脊迴歸使用
L2 正規化,也稱為 L2
懲罰(penalty),它是添加到誤差項的模型係數大小的平方。它只是簡單線性迴歸模型的擴展,可以更好地控制過度適配。脊迴歸模型方程與多元線性迴歸相同:
y = a + bX + cX2 + dX3 ……。

如果我們選擇的損失函數是 RMSE:
然後現在誤差變為:
Error = RMSE + λ (a2 + b2 + c2 +………)
這裡,λ 是正規化的水準。
脊迴歸分析的好處和應用
處理過度適配,使模型通用化好。縮小模型係數,降低模型複雜度和多重共線性。在任何現實世界的場景中,脊迴歸總是比線性迴歸更好的方法,因為它能夠學習通用模式而不是噪聲。
脊迴歸分析的局限性和假設
脊迴歸是線性迴歸模型的核心,因此只能用於對線性關係進行建模。它對線性迴歸模型做出了大多數假設。
(14) Lasso迴歸
Lasso 也是線性迴歸的擴展,但它實現了 L1 正規化而不是 L2。 L1 和
L2 之間的唯一區別是不考慮係數的平方,而是考慮幅度。
現在的誤差是:
Error = RMSE + λ(|a| +| b| +| c| +………)
誤差 = RMSE + λ( |a| +| b| +| c| +…………)
這裡,λ 用於控制正規化的水準。Lasso迴歸的目標是獲得最小化定量反應(因)變數的預測誤差的預測變數子集。它通過對模型參數施加約束來實現這一點,該約束導致某些變數的迴歸係數縮小到零。收縮過程後迴歸係數為零的變數從模型中排除。具有非零迴歸係數的變數與反應變數的相關性最強。因此,它有助於特徵選擇。
Lasso 迴歸分析的優點和應用
它避免了過度適配,可以在特徵數多於樣本數時使用。 Lasso
迴歸非常適合在潛在共變數數量較多且觀測值數量較少或大致等於共變數數量時,建立預測模型。它進行特徵選擇並通過它降低模型的複雜性。就測試數據的訓練和推理而言,它也很快。
Lasso 迴歸分析的局限性和假設
由於它的核心是線性模型,因此它遵循線性模型的大多數假設。它也無法進行分組選擇。它傾向於從一組變數中選擇一個變數而忽略其他變數。這不是很直觀,因為無法知道它為什麼選擇它所做的功能。它可能會在途中丟失一些重要的自變數,但這取決於正規化數值λ。
(15) ElasticNet迴歸
ElasticNet是 Lasso 和 Ridge Regression
的組合,因為它同時使用了 L1 和 L2 正規化。 Lasso 的特徵選擇可能過於依賴數據,因此不穩定,因此ElasticNet結合了這兩種方法來提供兩全其美的方法。
誤差公式:
Error = RMSE + λ α × L1 penalty+1- α ×L2
penalty
誤差 = RMSE + λ α × L1 penalty+1- α ×L2
penalty
在這裡,λ 用於像往常一樣控制正規化的水準,而 α 用於為 L1 和 L2
penalty賦予權重。該值始終介於 0 和 1 之間。
ElasticNet迴歸分析的優點和應用
處理過度適配,也可以使用 L1 正規化進行特徵選擇。由於存在 L2
penalty,可以執行分組選擇。它在稀疏 PCA 和新的支持內核機器中有有趣的應用。它還用於癌症預後處理和投資組合最佳化。
ElasticNet迴歸分析的局限性和假設
正規化導致降維,這代表著機器學習模型是使用低維數據集建立的。這通常
會導致高偏差誤差。同樣,它遵循線性模型的所有假設。
(16)貝葉斯線性迴歸
貝葉斯迴歸用於找出迴歸係數的值。在貝葉斯線性迴歸中,確定特徵的後驗分佈而不是尋找最小平方和。貝葉斯線性迴歸是線性迴歸和脊迴歸的組合,但比簡單的線性迴歸更穩定。另外一些類型的迴歸分析,它們可用於訓練迴歸模型以建立具有連續值的預測。
(17) 決策樹迴歸
顧名思義,決策樹是根據條件原則工作的。它是高效的,並且具有用於預測分析的強大算法。它主要歸因於包括內部節點、分支和終端節點。每個內部節點都持有一個屬性的“測試”,分支持有測試的結論,每個葉節點都表示類標籤。它用於分類和迴歸,它們都是監督學習算法。決策樹對它們準備的資訊非常敏感,準備集的微小變化可能會帶來根本不同的樹結構。
(18)隨機森林迴歸
顧名思義,隨機森林由大量的單個決策樹組成,它們作為一個組工作,或者正如他們所說的那樣是,一個整體。隨機森林中的每一棵決策樹都會給出一個類預測,而得票最多的類別被認為是模型的預測。
隨機森林通過允許每棵樹從數據集中隨機抽樣並替換,從而產生各種樹。這被稱為裝袋。
為機器學習選擇正確的迴歸分析模型類型
正如我們已經知道的那樣,有多種迴歸分析技術,您選擇的一種將取決於以下幾個因素:
1.應變數的類型 - 連續的、離散的、基於計數的或基於時間的。
2.在模型中需要的通用化量。
3.您可以使用的假設類型 -
在假設的數量和模型對真實世界數據的準確性之間進行權衡。
4.您的數據是否存在偏差或異常值。
5.您的自變數之間是否存在關係。
6.你的預測變數和結果之間的關係,線性/非線性。 |