|
資料來源:
https://go.graphpad.com/ebook/5-regression-analysis-mistakes-new
複習:原則迴歸的分析
在我們進入討論一些常見的迴歸過程中犯的錯誤分析,讓我們快速介紹基本原則。迴歸分析幫助您了解依賴變數與獨立變數的關係,以幫助您做出預測。什麼你試圖從迴歸分析中學習是如何增加或減少你的自變數。你這樣做只是為為您的數據適稱模型。
該模型目的在描述關係完美。相反,您的目標是找到盡可能簡單的接近描述您的系統的模型。以便您了解系統,得出有效的科學結論,並設計新的實驗。
這是一個簡單的、真實的例子,你們中的大多數人可能遇到過,用以幫助理解迴歸分析的目標。
如果你開著一輛汽油車,你就會意識在您需要添加汽油的金額與車輛可以行駛多遠之間更多的關係。通過了解這兩個因素(花費在燃料上的金額和你可以旅行的距離)兩者之間的關係,你基本上是進行迴歸分析。更何況你也可以使用這種分析來預測未來的事件。如果您需要長途旅行並且知道你會開車多遠,你可以使用迴歸分析所描述的關係,估計你需要花多少錢加油。這是迴歸分析的一種簡單形式,但應用範圍很廣。
迴歸的想法
迴歸分析中的所有模型,將結果(Y)定義為一個或多個自變數(X)[函數。
目標是調整模型的參數值,來找到最接近你的數據的直線或曲線。
例如,對於線性迴歸,目標是找到最合適的斜率和截距的值最佳化距離數據線。具有非線性化的迴歸劑量反應曲線,目標是調整EC50的值(引起的濃度中間的回應最小值和反應最大值)和斜率曲線。
迴歸的目標
通常,科學家使用迴歸具有三個不同目標:
使模型適合您的數據是為了獲得最佳適稱值參數,或進行替代模型的適稱比較。如果這是你的目標,你必須仔細選擇一個模型(或兩個替代模型),並注意所有的結果。重點是獲得最佳適稱值參數,所以你需要了解那些參數科學的意思。
從曲線按順序適稱平滑曲線,或者繪製圖表具有平滑的曲線。如果這是你的目標,您可以純粹通過查看數據圖表和曲線。沒必要學很多理論。
根據你的數據與案例不同,簡單地適稱一條平滑曲線。在為了做出預測,你必須了解數據如何生成,以及為什麼你應該為數據選擇一個特定的模型及其參數。
迴歸分析的複雜性
儘管許多科學家比任何其他統計技術執行更多迴歸分析,許多結果顯示他們不理解基本原則。它是一個靈活而強大的工具。它可以也很複雜。
在此指南將幫助您了解普通迴歸分析錯誤,並提供建議你可以避免它們。
1.
使用線性迴歸而不是非線性迴歸
在使用數據線性迴歸分析之前,問問自己非線性迴歸是否可能更有意義與適合您的數據。
線性和非線性迴歸如何工作
由一個從X計算Y的簡單方程描述的一條線,斜率和截距(y=mx+b)。線性迴歸的目的是找到斜率(m)和截距的值(b),以定義最接近數據的線。就像線性迴歸,非線性迴歸也試圖找到使直線或曲線的參數值盡可能接近數據。
線性迴歸和非線性迴歸都可以找到參數。線性迴歸為斜率和截距。使直線或曲線盡可能接近數據。
更準確地說,這個過程試圖最小化點到曲線的垂直距離的平方值。
線性迴歸使用可以以數學來實現這一目標,用簡單的代數完全解釋。把數據放進去,答案就出來了。沒有歧義的機會。你甚至可以做手動計算,如果你願意的話。
非線性迴歸使用密集計算的迭代法,只能使用微積分和矩陣代數來解釋。該方法需要每個參數的初始估計值。
為什麼要最小化距離平方和?
在執行線性(或非線性)迴歸時,您需要您的曲線盡可能接近盡可能多的數據點。
直覺上,您可能認為最小化適稱線(或曲線)與數據點的實際距離的總和將起作用。然而,想像一條曲線經過較大數據集的兩個點:一個在距離2個單位,另一個距離8個單位。在這種情況下,總和距離為10個單位。第二種可能適稱曲線可以在5個單位的距離處通過這些相同的點每一次,距離總和都是10個單位。線性和非線性迴歸,假設量測誤差服從高斯分佈。因此,它更有可能兩個中等大小的偏差比有一個小的偏差和一大偏差。前面的示例計算平方距離的總和導致第一個值為68(82+22)適合,但第二次適合只有50(52+52)。以最小化總和的平方距離,對於數據所有點提供了最有可能直線(或曲線)是正確的。
線性迴歸是一種特殊的非線性迴歸案例
非線性迴歸可以適稱任何模型,包括線性。因此,線性迴歸只是非線性的一個特例迴歸。
即使你的目標是適稱一條直線通過你的數據,有很多情況選擇非線性迴歸是有意義的地方,而不是線性迴歸。
在使用非線性迴歸分析數據只是比使用線性迴歸稍微困難一些,你的選擇線性或非線性迴歸應該根據您需要的模型。
提示:避免過時的數據轉型
如果您已轉換非線性數據來建立線性關係,幾乎使用非線性的原始數據進行迴歸肯定會更好。
在非線性迴歸很容易使用之前,分析非線性數據的最佳方法,是將數據轉換為建立一個線性圖,然後用線性迴歸分析轉換的數據。
示例包括Lineweaver-Burk酶動力學數據圖,Scatchard結合數據圖和對數圖動力學數據圖。
線性迴歸假設散點線周圍的點數,遵循高斯分佈分佈,
X的每個值標準差都相同。這些假設轉換數據後很少為真。
這些轉換數據方法已經過時,應該不能用於分析數據。
這些轉換數據方法的問題是轉換扭曲了實驗誤差。線性迴歸假設點的分散服從高斯分佈,並且標準差在X的每個值上都是相同的。轉換數據後這些假設很少是正確的。
此外,一些變換改變X和Y.例如,在Scatchard圖中,X的值代表濃度配體的由受體結合,而Y代表結合配體的濃度與游離配體濃度比例([結合]/[游離])。當進行線性迴歸時,X([bound])用於計算Y([bound]/[free]),但這違反了線性迴歸假設中所有不確定性都在Y中,而X已知。如果同樣的實驗錯誤出現在X和Y方向,點到線的距離垂直的平方和最小化沒有意義。
由於線性迴歸的假設被違反,從轉換值產生迴歸的斜率和截距線,不是測定模型中最準確的的變數。
考慮到你所有的時間和精力投入收集數據,你想使用最好的分析技術你的數據。以非線性迴歸產生最準確的結果。
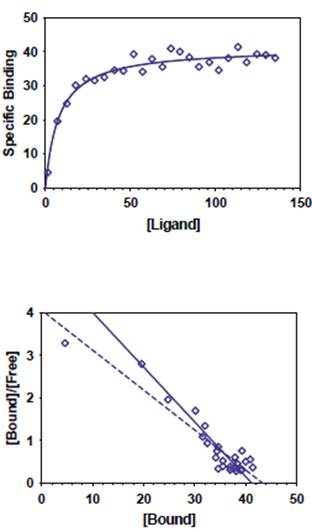
轉換數據的問題
這裡的圖顯示了轉換數據的問題。上圖顯示遵循矩形雙曲線(結合等溫線)的數據。這圖示是相同數據的Scatchard圖。上圖的實曲線由非線性迴歸確定。底部的實線顯示了相同的曲線,會執行Scatchard轉型。相反,下圖中的虛線顯示由線性迴歸生成的線,其適稱數據後已經被改造了。Scatchard圖可用於確定受體數(Bmax,確定為線性迴歸線的X截距)和平衡解離常數(Kd,確定為負斜率的倒數)。由於Scatchard變換放大並扭曲了點的分散,執行線性迴歸適稱轉換值後,不會產生最準確的Bmax和Kd值。
線性變換仍然有用,但不適用於分析不合適轉換後的數據,通常它是有助於顯示數據變換後線性分佈。很多人發現更容易以視覺解釋轉換後的數據。
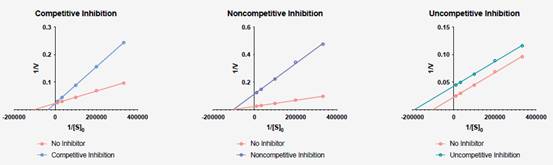
舉個例子,這些Lineweaver-Burk圖顯示抑制酶底物反應的各種類型。使用這些線性變換,你可以很快看到為競爭與抑制兩者線在y軸相交,而對於非競爭性抑制線相交於x軸,對於非競爭性抑制線兩者是平行的。使用線性變換呈現數據並製作快速,這樣的一般的推論是可以接受,但非線性迴歸仍應用於計算所需參數從你的數據。
底線:不要為了避免使用非線性而使用線性迴歸。使用非線性迴歸適稱曲線並不困難,而且為您的數據參數提供更準確的估計。
2.混淆線性迴歸與相關
首先,相關性和線性迴歸不是相同的。理解這些術語及其差異將幫助您避免錯誤混淆這兩個看似相似的概念。

什麼是相關性?
線性迴歸是一種用於找到來自X可以預測Y值的最佳線。相比之下,相關性是一種用於量化兩個變數相關的程度的技術。
但是相關性不符合一條線通過數據點。這種技術僅用於計算相關性係數(r)。告訴你一個變數傾向於隨著另一個變數而改變的多少變化。r的值提供此資訊:當r為0.0時,沒有關係。當r為正時,趨勢在數據中是一個變數的增加是隨著其他變數的增加。當r為負,趨勢是一個變數隨著另一個減少而增加。這r的值可以在+1到-1的範圍內。並提供關於這兩個變數是相關的“強烈”程度的一些資訊。就是這樣!
那麼有什麼區別呢?
除了線性迴歸生成一條線,和相關性只是提供了一個變數如何趨向另一個變數的相互改變,在這兩種技術之間有一些重要的區別。第一,線性迴歸通常用於X是您操縱的變數(時間,濃度等)以獲得量測值對於Y。在這種關係中,X是稱為“自變數”,而Y是“因”變數。
例如,假設您想要量測暴露於環境中不同數量的陽光其植物的生長。你會選擇不同的陽光照射時間(你的X或自變數)和你將衡量由此產生的增長(您的Y或因變數)。
相反,相關性幾乎總是量測兩個變數時使用。它當一個變數是你通過實驗操作的東西。比如說,你想看到身高和體重的關係各種職業運動員。你可以收集一個不同的球員的兩個量測值數字,但你不會以實驗確定。
這兩者之間的另一個區別技術是決定哪個你稱之為“X”的變數和稱之為“Y”的變數。這在迴歸中很重要。最好的線是從X預測Y與從Y預測X的線(科學上,這通常是沒有意義的)。
有了相關性,您不必思考關於因果。您將兩個變數中的哪一個稱為“X”和你稱之為“Y”都沒關係。
比如說,你想看到身高和體重的關係各種職業運動員。你可以收集一個數字的兩個量測值不同的球員,但你不會實驗確定。
底線
到目前為止,您已經看到線性迴歸和相關性是絕對不是一回事。然而這兩種技術確實有一些相似之處。
線性迴歸量化了確定的適稱優良度,符合術語為“r2”,有時顯示為“R2”。如果你將相同的數據關聯起來,來自相關性的r的平方將等於從迴歸R2。
3.
對於平滑數據進行模型適稱
你不應該對於滾動的平均數據,進行適合線性或非線性迴歸模型,或計算相關性係數。
問題是迴歸假設每個數值都是獨立,但滾動平均值根本不是彼此獨立。相反,每個值都作為包含自己在內的相鄰值一部分。
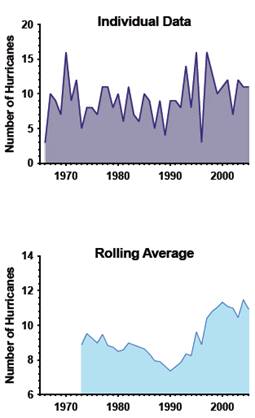
說明性示例:隨時間推移的颶風
這裡的數字顯示了颶風的數量隨時間的變化。這上圖顯示了每年的颶風數量,其中跳來跳去很多。為了更容易發現趨勢,下圖顯示滾動平均值。每年繪製的數值是當年颶風次數的平均值加上前八年。這種平滑可以讓您看到明顯的趨勢。但有一個問題。這些不是真實數據。相反,數值是隨機選擇的(來自Poisson分佈,平均值為10)。沒有模式。每個值都是隨機生成而不考慮之前(或之後)的gj4值。
底線:運行建立的平均值會通過確保任何大的隨機擺動,到高值或低值此趨勢放大,而可變性被抑制。這充其量是誤導,而且經常使研究無效。
4.刪除或不刪除:
非線性迴歸,如線性迴歸,其假設是理想曲線周圍的數據分散,遵循高斯或常態分配。這一假設導致熟悉的迴歸目標:最小化垂直的平方和或點和曲線之間的Y值距離。
但是,實驗錯誤可能導致錯誤值異常值。即使是單個異常值也可能主導影響平方和計算,並導致誤導性結果。
去除異常值是“作弊”嗎?
有些人認為去除異常值是“作弊”。它可以在臨時刪除異常值時以這種方式查看方式,尤其是當僅刪除進入的異常值時,獲得你喜歡的結果的方式。但是您分析的數據留下異常值也可能被視為“作弊”,因為它可能導致無效的結果。
一種去除異常值的方法
這是貝葉斯的思考方式,異常值系統的去除方法。當一個數值被標記為異常值,有兩種可能。
•巧合發生了,那種發生在百分之幾的巧合的實驗,即使整個scatter是高斯分佈的(取決於如何積極地定義一個異常值)。
•您的數據中包含一個“壞”點。
哪種可能性更大?它取決於你的實驗系統。
如果您的實驗系統在百分之幾的實驗中生成一個“壞”點,那麼作為異常值消除是有意義的點。它更有可能成為一個“壞”點而不是一個“好”點,剛好離曲線很遠。
如果您的系統非常純淨且受控,“壞”點很少發生。更有可能是由於偶而機會而遠離曲線,你應該離開它或者。在這種情況下,您可以更改定義異常值的臨界值。為了只是檢測遠得多的異常值。
請記住,異常值不是總是“壞”點
在某些情況下,數據點在首先出現的異常值可能不是由實驗錯誤引起,而是生物的結果變化,或未包含在您的變數中的變數模型其他一些差異。在這裡,異常值的存在可能是你的學習最有趣的發現。這種情況沒有進一步考慮(或實驗),自動排除此類異常值這將是一個很大的錯誤。
刪除“壞”點不一定是壞事,但是異常值也可能告訴你一些事情對你的研究很重要。
底線
當然,在某些情況下,您需要刪除異常值。在這樣做之前考慮每種情況提高準確性。刪除“壞”點不一定是壞事,但異常值也可能告訴你對你的研究很重要的一些事情。
5.允許程式為您選擇型號
非線性迴歸的目標是使模型適合您的數據。程式發現模型中參數的最佳適稱值(可能是速率常數,親和力、受體數量等),您可以對其進行科學解釋。
選擇模型是一個科學的決定。你應該根據您對化學、生理學、或遺傳學等的理解做出選擇。選擇不應僅基於數據在你的圖表上的形狀。
但是有些程式會自動將數據適稱到數以千計的方程式,然後呈現給你最適合數據的方程式。使用這樣的程式很有吸引力,因為它讓你擺脫了需要自行選擇一個方程式。
問題是電腦程式沒有理解你的實驗的科學背景。
最適合數據的方程式不太可能對應於具有科學意義的模型。你將無法解釋的最佳適稱值參數,因此結果不太可能有用。
如果您的目標是簡單地建立平滑曲線,讓程式為您選擇模型是可以。用於模擬或內插值則很有用。在這些情況下,你不關心參數的值或模型的意義。你只關心曲線很好地適稱數據,並且不會擺動太多。這種方法基於化學、物理或生物學原理,要避免曲線適稱的目標只是為了適稱。
選型是科學的決定
你應該根據你的選擇關於你對化學的理解或生理學(或遺傳學等)。這選擇不應該僅僅基於圖表上數據的形狀。
底線:
不要使用電腦程式來避免理解您的實驗系統,或避免做出科學決策。 |