|
資料來源:
https://towardsdatascience.com/the-ultimate-guide-to-data-cleaning-3969843991d4
在過去的幾個月裡,我分析了來自感測器、調查和日誌的數據。無論我建立了多少圖表,演算法多麼複雜,結果總是具有誤導性。

向數據隨機投擲與向數據注入病毒相同。這種病毒除了會損害您的洞察力,就好像您的數據在噴吐垃圾一樣,沒有其他用途。
更糟糕的是,當你向 CEO
展示你的新發現時,哎呀,你猜怎麼著?他/她發現了一個缺陷,一些聞起來不對勁的東西,你的發現與他們對領域的理解不符。畢竟,他們是比你更了解的領域專家,你是分析師或開發人員。
鮮血馬上湧上你的臉,雙手顫抖,沉默片刻,然後,大概是道歉。
這一點孩不算壞。如果您的調查結果被用作保證,而您的公司最終根據這些結果做出決定怎麼辦?
你攝取了一堆髒數據,沒有清理它。你告訴你的公司對這些結果做一些事情,結果證明是錯誤的。你會遇到很多麻煩!
不正確或不一致的數據會導致錯誤的結論。因此您對數據的清理和理解程度對結果的品質有很大影響。
維基百科上給出了兩個真實的例子。
例如政府可能希望分析人口普查數據,以確定哪些地區需要在基礎設施和服務方面進一步支出和投資。在這種情況下,獲得可靠數據以避免錯誤的財政決策非常重要。
在商業世界中,不正確的數據可能代價高昂。許多公司使用客戶資訊數據庫來記錄聯繫資訊、地址和偏好等數據。如果地址不一致,公司將承擔的成本包括重新發送郵件甚至失去客戶。
垃圾進,垃圾出。
事實上,一個簡單的演算法可以勝過一個複雜的演算法,因為只要有足夠的高品質數據。
品質數據勝過花哨的演算法。
由於這些原因,制定分步指南(即備忘清單)非常重要,該指南貫穿要應用的品質檢查。
但是首先,我們想要實現的目標是什麼?品質數據是什麼意思?品質數據的衡量標準是什麼?要了解您要完成的工作,在採取任何行動之前,您的最終目標十分重要。
數據品質
Wikipedia上的品質標準,我找不到更好的解釋。所以在這裡總結一下。
有效性
數據符合定義的業務規則或約束的程度。
數據類型約束:特定列中的值必須是特定數據類型,例如布爾值、數字、日期等。
範圍約束:通常數字或日期應在一定範圍內。
強制約束:某些列不能為空白。
唯一約束:一個字段或字段組合在數據集中必須是唯一的。
集合成員約束:列的值來自一組離散值。例如一個人的性別可能是男性或女性。
外鍵約束:與關係數據庫一樣,外鍵列不能具有引用主鍵中不存在的值。
正則表達式模式:必須採用特定模式的文本字段。例如電話號碼可能需要具有
(999) 999–9999 模式。
跨領域驗證:跨越多個領域的某些條件必須成立。例如患者的出院日期不能早於入院日期。
準確性
數據接近真實值的程度。
雖然定義所有可能的有效值,可以很容易地發現無效值,但這並不代表著它們是準確的。
一個有效的街道地址可能實際上並不存在。一個有效的人的眼睛顏色,比如藍色,可能是有效的,但不代表現實是真的。
另一個需要注意的是準確性和精確度之間的差異。說你住在地球上是真的。但是不精確。地球上的什麼地方?說你住在一個特定的街道地址才更準確。
完整性
了解所有所需數據的程度。
由於各種原因,丟失數據將會發生。如果可能的話,可以通過質疑原始來源來紓解這個問題,比如重新採訪該主題。
很有可能,該主題不是會給出不同的答案,就是將難以再次觸及。
一致性
數據在同一數據集內或跨多個數據集的一致性程度。
當數據集中的兩個值相互矛盾時,就會發生不一致。
有效年齡(例如 10
歲)可能與婚姻狀況(例如離婚)不匹配。客戶記錄在兩個不同的表中,有兩個不同的地址。
那麼哪一個是真的?。
均勻度
使用相同的度量單位指定數據的程度。
重量可以用磅或公斤記錄。日期可能遵循美國格式或歐洲格式。貨幣有時是美元,有時是日元。因此必須將數據轉換為單個度量單位。
工作流程
工作流程是一系列三個步驟,目的在產生高品質的數據並考慮到我們討論過的所有標準。
檢查:檢測意外、不正確和不一致的數據。
清理:修復或刪除發現的異常。
驗證:清洗後,檢查結果以驗證正確性。
報告:記錄有關所做更改和當前存儲數據品質的報告。
您所看到的順序過程實際上是一個迭代的、無止境的過程。當檢測到新缺陷時,可以從驗證到檢查。
檢查數據
檢查數據非常耗時,並且需要使用多種方法來探索基礎數據以進行錯誤檢測。這裡是其中的一些方法:
數據分析
有關數據的匯總統計資訊(稱為數據分析)確實有助於大致了解數據的品質。
例如檢查特定列是否符合特定標準或模式。數據列是記錄為字符串還是數字?
缺少多少值?一列中有多少個唯一值,以及它們的分佈?此數據集是否與另一個鏈接或有關係?
可視化
通過使用統計方法(例如平均值、標準差、範圍或分位數)分析和可視化數據,可以找到意外並因此發現錯誤的數值。
例如通過可視化各國的平均收入,人們可能會看到一些異常值。有些國家的人收入比其他任何人都多。這些異常值值得調查,不一定是不正確的數據。
軟體套件
您的語言中可用的幾個軟體套件或庫軟體將允許您指定約束並檢查數據是否違反這些約束。
此外不僅可以生成違反了哪些規則以及違反了多少次的報告,還可以建立一個圖表,說明哪些列與哪些規則相關聯。
例如,年齡不能為負數,身高也不能為負數。其他規則可能涉及同一行或跨數據集的多個列。
清洗
數據清洗涉及基於問題和數據類型的不同技術。可以應用不同的方法,每種方法都有自己的權衡取捨。
總體而言,不正確的數據步是被刪除、更正就是被估算。
無關數據
不相關的數據就是那些實際上不需要的數據,並且不適合我們試圖解決的問題的背景。
例如如果我們正在分析有關人口總體健康狀況的數據,則電話號碼將不是必需按列排列的。
同樣如果您只對一個特定國家/地區感興趣,您不會希望包括所有其他國家/地區。或者只研究那些接受手術的患者,我們不會包括每個人。
只有當您確定某條數據不重要時,您才可以刪除它。否則探索特徵變數之間的相關矩陣。
即使您沒有發現相關性,您也應該詢問領域專家。你永遠不會知道,一個看似無關緊要的特徵,從不同領域的角度(例如臨床角度)可能是非常相關的。
重複
重複項是在數據集中重複的數據點。
它經常發生在例如:
數據來自不同的來源
用戶可能會點擊提交按鈕兩次,以為表單實際上並未提交。
提交了兩次在線預訂請求,更正了第一次意外輸入的錯誤資訊。
一個常見的症狀是兩個用戶具有相同的身份號碼。或者同一篇文章被廢棄了兩次。因此它們應該被刪除。
類型轉換
確保數字存儲為數字數據類型。日期應存儲為日期對像或
Unix 時間戳(秒數)等。
如果需要,可以將分類值轉換為數字。
這可以通過查看摘要中每一列的數據類型來快速發現。
需要注意的是,無法轉換為指定類型的數值應轉換為
NA 值(或任何值),並顯示警告。這表明該值不正確,必須修復。
語法錯誤
刪除空格:應刪除字符串開頭或結尾的多餘空格。
“你好世界”=>“你好世界
填充字符串:字符串可以用空格或其他字符填充到一定的寬度。例如一些數字代碼通常用前置零表示,以確保它們始終具有相同的位數。
313 => 000313(6
位)
修正拼寫錯誤:字符串可以通過多種不同的方式輸入,難怪會出現錯誤。
性別
m
Male
fem.
FemalE
Femle
這個分類變數被認為有 5
個不同的類,而不是預期的 2 個:男性和女性,因為每個值都不同。
條形圖對於可視化所有唯一值很有用。人們可以注意到一些值不同但確實代表著相同的東西,即“資訊技術”和“IT”。或者,也許區別僅在於大小寫,即“other”和“Other”。
因此,我們的職責是從上述數據中識別每個值是男性還是女性。我們怎麼能這樣做?
第一個解決方案是手動將每個值映射到“男性”或“女性”。
['gender'].map({'m':
'male', fem.': 'female', ...})
第二種解決方案是使用模式匹配。例如,我們可以在字符串開頭的性別中查找
m 或 M 的出現。
re.sub(r"\^m\$",
'Male', 'male', flags=re.IGNORECASE)
第三種解決方案是使用模糊匹配:一種識別預期字符串與每個給定字符串之間距離的演算法。它的基本實現計算將一個字符串,轉換為另一個字符串需要多少操作。
Gender malefemale
m 35
Male13
fem.53
FemalE32
Femle 31
此外,如果有像城市名稱這樣的變數,那麼您懷疑錯別字或類似的字符串應該被同等對待。例如“lisbon”
can be entered as “lisboa”, “lisbona”, “Lisbon”, etc.
City Distance from "lisbon"
lisbon 0
lisboa 1
Lisbon 1
lisbona2
london 3
...
如果是這樣,那麼我們應該將所有具有相同含義的值替換為一個唯一值。在這種情況下,將前 4
個字符串替換為“lisbon”。
注意諸如like “0”,
“Not Applicable”, “NA”, “None”, “Null”, or “INF””之類的值,它們的含義可能相同:缺少值。
標準化
我們的職責是不僅要識別錯別字,還要將每個值放在相同的標準化格式中。
對於字符串,請確保所有值都是小寫或大寫。
對於數值,請確保所有值都有特定的量測單位。
例如,高度可以以米和厘米為單位。
1米的差異被認為與1厘米的差異相同。因此,這裡的任務是將高度轉換為一個單位。
對於日期,美國版本與歐洲版本不同。將日期記錄為時間戳(毫秒數)與將日期記錄為日期對像不同。
縮放/轉換
縮放代表著轉換您的數據,使其適合特定的比例,例如
0–100 或 0–1。
例如學生的考試成績可以重新調整為百分比
(0-100) 而不是 GPA (0-5)。
它還有助於使某些類型的數據更容易繪製。例如,我們可能希望減少偏度以幫助繪圖(當有如此多的異常值時)。最常用的函數是對數、平方根和逆數值。
也可以對具有不同量測單位的數據進行縮放。
不同考試的學生成績說,SAT和ACT,因為這兩個考試的規模不同,所以無法比較。
1個SAT分數的差異被認為與1個ACT分數的差異相同。在這種情況下,我們需要重新調整
SAT 和 ACT 分數來取數字,比如
0-1 之間的數字。
通過縮放,我們可以繪製和比較不同的分數。
常態化
雖然歸一化也將值重新縮放到
0-1 的範圍內,但這裡的目的是轉換數據,使其呈常態分佈。為什麼?
在大多數情況下,如果我們要使用依賴於常態分佈數據的統計方法,我們會對數據進行標準化。如何?
可以使用日誌功能,或者也許使用這些方法之一。
根據使用的縮放方法,數據分佈的形狀可能會發生變化。例如,“標準
Z 分數”和“學生
t 統計量”保留了形狀,而對數函數可能不會。
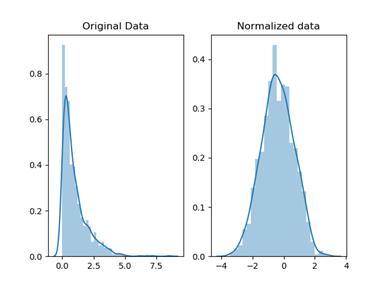
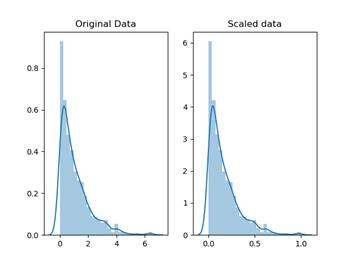
Normalization vs
Scaling (using Feature
scaling) — source
缺失值
由於缺失值是不可避免的,這給我們留下了當我們遇到它們時,該怎麼做的問題。忽略丟失的數據就像在船上挖洞一樣;它會下沉。
有三種或更多的方法來處理它們。
-
一。降低。
如果列中的缺失值很少發生並且隨機發生,那麼最簡單和最前瞻的解決方案是刪除具有缺失值的觀察值(行)。
如果大多數列的值都丟失了,並且是隨機出現的,那麼一個典型的決定是刪除整個列。
這在進行統計分析時特別有用,因為填充缺失值可能會產生意外或有偏差的結果。
-
二。歸責。
這代表著根據其他觀察結果計算缺失值。有很多方法可以做到這一點。
1.
第一個是使用平均值、中位數等統計值。但是這些都不能保證數據無偏差,尤其是在有很多缺失值的情況下。
偏斜時最有用,而中位數更穩健,對異常值不敏感,因此在數據偏斜時使用。
在常態分佈的數據中,可以獲得與平均值相差
2 個標準差以內的所有值。接下來,通過生成 (mean — 2 * std) & (mean
+ 2 * std)
rand =
np.random.randint(average_age - 2*std_age, average_age + 2*std_age, size
= count_nan_age)dataframe["age"][np.isnan(dataframe["age"])] = rand
2.
第二。使用線性回歸。根據現有數據,可以計算出兩個變數之間的最佳適稱線,例如房價與面積 m²。
值得一提的是,線性回歸模型對異常值很敏感。
3.
第三。 Hot-deck:從其他類似記錄中複制數值。這僅在您有足夠的可用數據時才有用。並且它可以應用於數值和分類數據。
可以採用隨機方法,用隨機值填充缺失值。將這種方法更進一步,可以首先根據某些特徵(例如性別)將數據集分為兩組(層),然後隨機分別填充不同性別的缺失值。
在sequential hot-deck中,包含缺失值的列,根據輔助變數進行排序,以便具有相似輔助變數的記錄順序出現。接下來,每個缺失值都用後面的第一個可用記錄的值填充。
更有趣的是,還可以使用k最近鄰插補,它對相似的記錄進行分類並將它們放在一起。然後通過首先查找最接近具有缺失值的記錄的k記錄來填充缺失值。接下來,從k最近的鄰居中選擇(或計算出)一個值。在計算的情況下,可以使用像平均值這樣的統計方法(如前所述)。
— Three. Flag.
一些人認為,無論我們使用何種插補方法,填寫缺失值都會導致資訊丟失。
那是因為說數據丟失本身就是資訊,演算法應該知道它。否則,我們只是通過其他功能加強已經存在的模式。
當丟失的數據不是隨機發生時,這一點尤其重要。以進行的調查為例,來自特定種族的大多數人拒絕回答某個問題。
缺失的數字數據可以用 0
填充,但在計算任何統計值或繪製分佈時必須忽略這些零。
雖然可以用“缺失”來填充分類數據:一個新的類別,表明該數據缺失。
考慮到缺失值與默認值不同。例如,零可以解釋為缺失或默認,但不能同時解釋為兩者。缺失值不是“未知的”。在一項進行的研究中,有些人不記得他們是否在學校被欺負過,應該被對待並標記為未知而不是失踪。
每次我們放棄或估算價值時,我們都會丟失資訊。因此標記可能會派上用場。
異常值
它們是與所有其他觀察結果顯著不同的值。任何距離
Q1 和 Q3 四分位數超過 (1.5
* IQR) 的數據值都被視為異常值。
在被證明有罪之前,異常值是無辜的。話雖如此,除非有充分的理由,否則不應刪除它們。
例如人們可能會注意到一些不太可能發生的奇怪、可疑的值,因此決定刪除它們。不過它們值得在刪除之前進行調查。
還值得一提的是,一些模型,如線性回歸,對異常值非常敏感。換句話說,異常值可能會使模型偏離大多數數據所在的位置。
記錄內和跨數據集錯誤
這些錯誤是由於在同一行中有兩個或多個值,或者在相互矛盾的數據集中有兩個或多個值。
例如,如果我們有一個關於城市生活成本的數據集。總列必須等於租金、交通和食物的總和。
city
renttransportation foodtotal
libson 50020 40560
paris75040 60850
同樣,孩子不能結婚。員工的工資不能低於計算的稅款。
同樣的想法適用於不同數據集的相關數據。
驗證
完成後,應通過重新檢查數據並確保其規則和約束確實成立來驗證正確性。
例如,在填寫缺失的數據後,他們可能會違反任何規則和約束。
如果不可能,它可能會涉及一些手動更正。
報告
數據報告的健康程度對於清理同樣重要。
如前所述,軟體套件或軟體庫可以生成所做更改、違反哪些規則以及違反次數的報告。
除了記錄違規之外,還應考慮這些錯誤的原因。為什麼他們首先發生?
最後的話……
如果你做到了那一步,我很高興你能堅持到最後。但是,如果不接受品質文化,所提到的一切都沒有價值。
無論驗證和清理過程多麼強大和強大,隨著新數據的出現,人們將繼續受到影響。
與其花時間和精力去治療它,不如保護自己免受疾病的侵害。
這些問題有助於評估和提高數據品質:
1.如何收集數據,以及在什麼條件下?收集數據的環境確實很重要。環境包括但不限於地點、時間、天氣狀況等。
在上班途中向受試者詢問他們對任何事情的看法與他們在家時不同。在一項研究中,使用平板電腦回答問卷有困難的患者可能會放棄結果。
2.數據代表什麼?它包括所有人嗎?只有城裡的人?或者,也許只有那些因為對這個話題有強烈意見而選擇回答的人。
3.
用於清理數據的方法是什麼,為什麼?在不同的情況下或使用不同的數據類型時,不同的方法可能會更好。
4.您是否投入時間和金錢來改進流程?投資於人員和流程與投資於技術同樣重要。 |