|
Biochem Med[Zagreb]2021;
31[1]:010502
https://www.researchgate.net/publication/347850883_Sample_size_power_and_effect_size_revisited_simplified_and_practical_approaches_in_pre-clinical_clinical_and_laboratory_studies
摘要
在科學研究中,計算樣本數是關於研究科學貢獻的關鍵問題之一。樣本數量嚴重影響假設和研究設計,並且沒有直接的方法可以來計算有效樣本數量以得出準確的結論。統計上不正確使用的樣本數可能會導致臨床和實驗室研究的結果不足,並導致時間損失,成本和道德問題。此評論有兩個主要目的。第一個目的是解釋樣本數與統計的顯著性及效應大小(ES,
effect size)的關係。第二個目的是協助 研究人員計劃通過可用於不同科學目的的替代軟體,指南和參考資料來進行樣本數估計。
關鍵字:生物統計學;效應大小; 檢定力分析;樣本數
介紹
統計分析是研究的關鍵部分。一個科學研究必須包括從規劃階段開始在研究使用的統計工具。發達國家在過去的20 -
30年,資訊技術,與實證醫學一起,增加了統計等的傳播和應用。儘管科學家已經了解了統計分析對研究人員的重要性,有顯著數目的研究者承認,他們缺乏關於統計等足夠的知識概念和原則[1]。Wert和Ficalora的研究,超過三分之二的臨床醫生強調的是“提供給醫學生生物統計學教育水準是不夠的” [2]。結果表明,統計概念不是理解不清,就是根本不理解[3,4]。另外研究人員有意或無意地得出結論,但是往往不能得到實際研究數據的支持,這是由於統計工具的誤用[5]。其結果是大量的統計錯誤影響了研究成果。
儘管在任何類型的科學研究中都可能會發生各種潛在的統計錯誤。但是已經發現,研究錯誤已經有了變化是由於近年來使用了統計的專用軟體。科學研究中經常遇到的主要統計錯誤,摘要如下[6-13]:
1.
虛假的和不充分的假設;
2.
不適當的試驗;
3.
缺乏適當的控制條件/組;
4.
頻譜偏差
5.
高估分析結果;
6.
虛假相關;
7.
樣本數不適當;
8.
循環分析(通過回顧性地選擇數據屬性來產生偏差);
9.
利用不適當的統計研究和分析的謬誤;
10.
P-hacking(即事後添加新的共變數以使P值顯著);
11.
對結果有限或不顯著的過多解釋(主觀主義];
12.
相關性,關係和因果關係的混淆(有意或無意);
13.
錯誤的多元回歸模型;
14. P值與臨床顯著性之間的混淆
15.
結果和效果的不當表示(錯誤的表格,圖示和圖形)。
Part 1. 樣本數,檢定力,P值和效應大小之間的關係
在這篇評論中,將集中討論與樣本數,檢定力,P值和效應大小[ES]之間的關係。儘可能的情況下將提供實際的建議。為了理解和解釋樣本數,檢定力分析,效應大小和P值,有必要知道研究假設是如何形成的。最好的評估一項研究其I型和II型錯誤(圖1.)。通過在其研究結果所考慮的研究前提[14-16]。

統計假設是研究者,什麼實驗將顯示甚麼的結果最好的猜測。它以可測試的形式陳述了研究人員在樣本計劃中檢查的命題,以便能夠找出該命題在相關母群中是否正確。統計中有兩種常用的假設類型。這些是虛無假設(H0)和對立假設(H1)。本質上,H1是研究人員的預測針對實驗組採用實驗治療後的情況。H0表示此實驗處理不會產生任何效應。
在研究之前,除了設定陳述假設之外,研究者還必須選擇alpha(α)水準,假設將被宣佈為“受支持”的信賴水準。該α代表了研究員願意承擔多大的風險。對於這項研究結束後認為H1是正確的,而對母群而言,這是不正確的。因此,在虛無假設是正確的。換句話說,alpha表示當H0確實為真時,拒絕H0的概率。因此,研究人員在研究報告說實驗性治療有明顯不同,而實際上在整個母群中卻沒有效應,因此造成了錯誤。
最常見的α選擇水準為0.05,這代表著研究者願意以5%的機會,支持這一假設結果是在整個母群終將是不真實的。然而,其他的α水準也可以在某些情況下適當的選用。對於先期研究,α通常假設為0.10或0.20。在特別重要的研究,是為了避免結論是有效,然而實際上治療無效。此情況可以將alpha值假設很低。它可能假設為0.001甚至更低。藥物研究是經常將alpha假設為0.001或更低的研究的範例,因為釋放無效藥物的後果,對患者來說是極其危險的。
另一個概率值稱為" P值"。P值只是錯誤地接受對立假設的統計概率。將P值與alpha值進行比較,以確定結果是否“具有統計學顯著意義” 。這代表著在樣本中發現的結果在整個母群中也是如此的機率。如果P值等於或小於alpha,則接受H1。如果它高於alpha,則拒絕H1,而是接受H0。
實際上有兩種類型的錯誤:在母群中不可接受H1時,卻接受H1的錯誤。這稱為I類錯誤;是錯誤的報告,稱為偽陽性。
alpha定義了發生I類錯誤的可能性。發生I類錯誤可能有多種原因,從取樣不正確,因而母群樣本與實驗樣本完全不同,到在設計階段或研究程序實施過程發生其他錯誤。也有可能對於相反方向做出錯誤的決定。這是也可以使一個錯誤的決定相反的方向。錯誤地拒絕了H1,從而接受了H0。這稱為II型錯誤(或偽陰性)。β定義是發生II型誤差的概率。造成這種類型錯誤的最常見原因是樣本數目小,尤其是與中低或較低的效應直結合使用時。小的樣本數目和低的效應大小都降低了研究的檢定力。
檢定力即拒絕錯誤虛假假設的概率,但計算為1- β。也表示為1-
(II型錯誤概率)。對於一個II型錯誤0.15,檢定力為0.85。由於降低犯下第II型錯誤的可能性,則會增加犯下第I型錯誤的風險。反之亦然。因此應在I型和II型錯誤的最小允許程度之間建立微妙的平衡。研究的理想檢定力被認為是0.8,也可以說指定為80%[17]。應該保持足夠的樣本數,以使得I型誤差低至0.05或0.01,檢定力高至0.8或0.9。但是,當檢定力值降至<0.8以下時,人們無法立即得出結論以認為這項研究完全毫無價值。近年來與此並行的概念,有效成本的樣本數目”已經得到了重視,[18]。
此外,傳統上選擇alpha和beta的誤差極限通常是任意的,被作為慣例而不是基於有效的任何科學理論。研究的另一個關鍵問題是研究效應大小的確定,呈現和討論,這將在下面進行詳細討論。
儘管建議增加樣本數量可以減少II型錯誤,但它將增加研究項目成本並在可預見的時間內延遲完成研究活動。此外不應忘記多餘的樣本可能會導致道德問題[19,20]。因此,有效樣本數的確定對於進行有效研究具有重要意義,對於增加結果的影響力至關重要。不幸的是,在大多數診斷研究中,臨床研究人員通常不提供有關樣本數計算的資訊[21,22]。
樣本數的計算
在研究開始之前,可以使用不同的方法計算最適合特定研究的樣本數。除了手工計算外,還可以使用各種列線圖(nomograms)或軟體。圖2說明了一種利用效應大小和檢定力以估算樣本大小最常用的列線圖[23]。
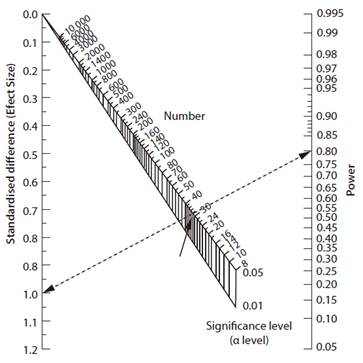

儘管手動計算是各領域專家的首選,但對於不是統計專家的研究人員來說,這有些複雜且困難。此外,考慮各種的研究類型和其特點,它應該被注意的是,有太多的變數的研究其計算的數量巨大(表1.)要求[16,24-30]。



近年來,開發了許多軟體和網站,可以針對各種研究類型成功計算樣本數。表2.列出了一些重要的軟體和網站,並根據文獻中的評論和我們的經驗對其內容,易用性和成本進行了評估[31,32]。G-POWER,R,和Piface
代表在上市軟體之中可以自由使用。G-POWER是一款免費使用的工具,被用來計算統計檢定力,包括許多不同的t -檢定,F檢定,χ 2檢定,z-檢定和一些精確檢定。
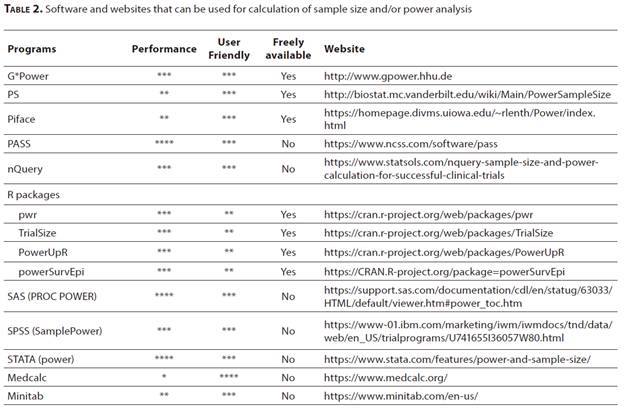
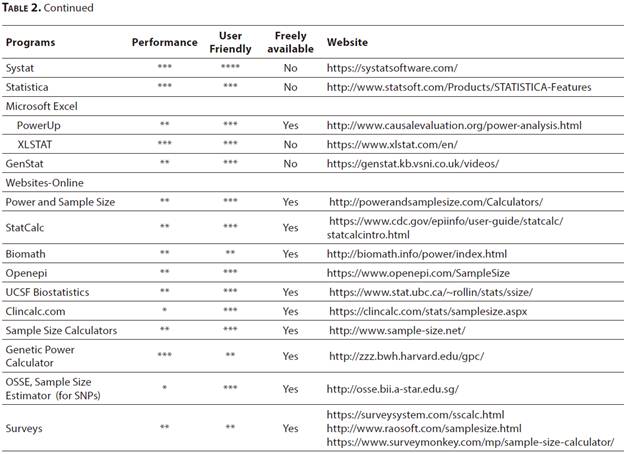
圖2.樣本數和檢定力的列線圖,用於比較兩組相同大小的樣本。其假定為高斯分佈。首先在列線圖上選擇標準化差異[效應大小]和目標檢定力值。連接這些值的線越過列線圖的顯著性水準區域。將在適當的顯著水準與所需的研究的樣本數交會。在上面的例子中,對於效應大小=
1,檢定力= 0.8,alpha值=
0.05,可發現樣需要的本大小為30。[改編自參考文獻16]。
R是一種開放源代碼編程語言,可以通過增加特定模組來滿足各種統計需求。Pi face是專門用於樣本大小估計和事後檢定力分析的Java應用程序。最專業的軟體是PASS(檢定力分析和样本量)。通過PASS,可以分析大約200種不同研究類型的樣本大小和檢定力。此外,許多網站都以科學文獻的方法為基礎,在計算檢定力和样本量方面提供了實質性幫助。
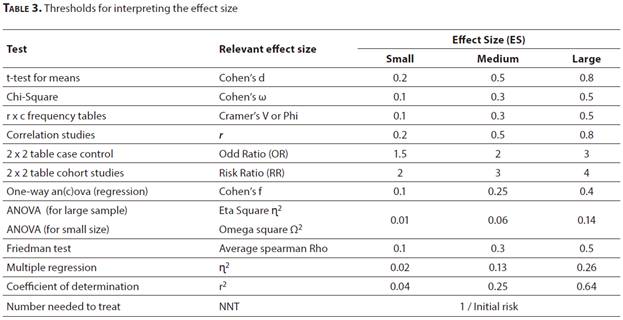
樣本數或研究的檢定力與研究的效應大小直接相關。這個重要的效應大小是什麼?效應大小提供了有關自變數或變數對他變數的預測程度的重要資訊。較低的效應大小表示自變數的預測效應不佳,因為它們與依他變數的關係很小。強大的效應大小代表著自變數是依他變數的非常好的預測因子。因此,效應大小對於評估臨床醫學研究,從獨立變數預測結果的效率方面具有重要的臨床意義。
表3列出了在不同研究類型中進行的不同統計測試的效應大小值的規模。為了評估研究的效應並表明其臨床意義,評估效應大小以及統計顯著性非常重要意義。P值在研究的統計評估中很重要。儘管它提供有關效應存在/不存在的資訊,但不會考慮效應的大小。為了全面介紹和解釋研究,應同時提供和考慮效應大小和統計顯著性(P值)。通過示例來理解效應大小會容易得多。例如,假設使用獨立樣本t檢定,比較具有常態分佈的兩組的總膽固醇水準。
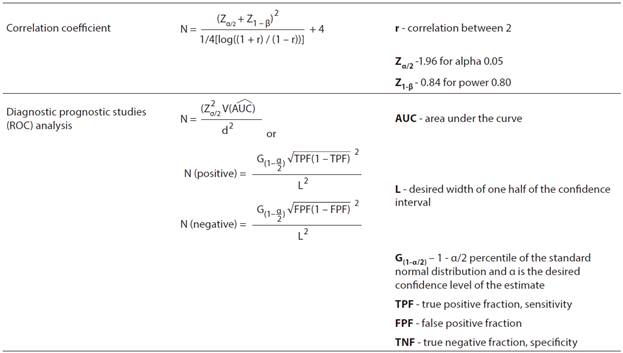
其中X,SD和N分別代表平平均值,標準差和样本量。Cohen’s
d 效應大小可以計算如下:
|
|
X |
SD |
N |
|
Group1 |
6.5 |
0.5 |
30 |
|
Group2 |
5.2 |
0.8 |
30 |
t值=-7.54,P
<0.001
Cohen d
ED =[X1 - X2]/ SDp =[6.5-5.2]/ 0.67 = 1.3 / 0.67 = 1.94
Cohen d
效應大小結果代表效應:0.8大,0.5個中等,0.2個小。1.94的結果表明效應非常好。兩組的平平均值明顯不同。
在上面的示例中,兩組的平均值在統計學上顯著不同。但是,該效應的臨床顯著性需要由本領域的專家進行專門評估。該效應對患者,臨床狀況,治療類型,結果等十分重要。
檢定力,alpha值,樣本大小和效應大小彼此密切相關。通過使用G-Power[33,34]建立的不同情況來解釋這種關係。
圖3.顯示了樣本大小隨效應大小變化[分別為0.2、1和2.5]而變化的情況。前提是檢定力保持恆定在0.8。可以說,案例3在臨床前研究,細胞培養和動物研究中特別常見在動物研究中通常為5-10個樣本,在細胞培養研究中為3-12個樣本,案例2在臨床研究中更常見。在臨床,流行病學或meta分析研究中,樣本數非常大;案例1強調了較小效應的顯著性,這種情況為常見情況。[33]。
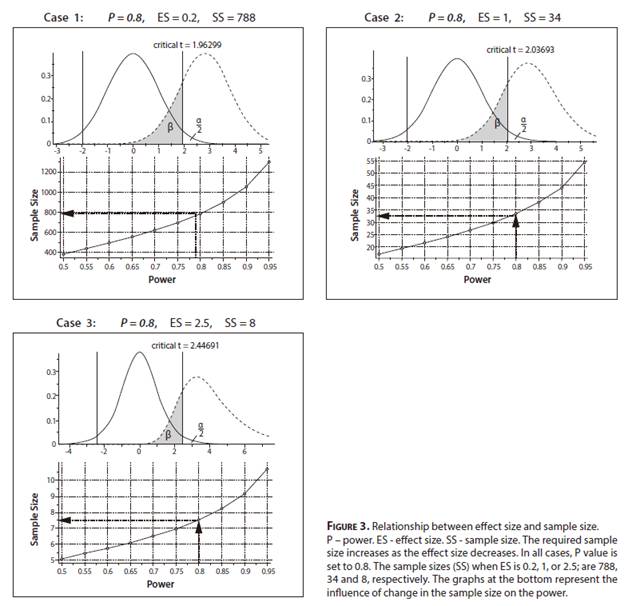
在圖4.中,情況4舉例說明了當樣本大小保持恆定(例如低至8)時,檢定力和效應大小值的變化。從這裡可以看出,在低效應大小的研究中,處理很少的樣品將代表著浪費時間,重複處理或不必要地使用實驗動物。
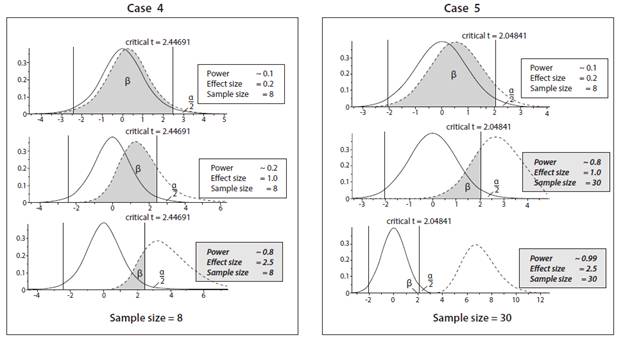

同樣,情況5舉例說明了樣本數保持恆定為30的情況。在這種情況下重要的是要注意,當效應大小為1時,研究的檢定力約為0.8。一些統計學家任意地將30作為關鍵樣本數。但是案例5清楚地表明,在確定樣本數的同時,不要低估效應大小的顯著性。
圖3.效應大小和样本量之間的關係。P –檢定力。效應大小-效應大小。SS-樣本數量。隨著效應量的減少,所需的樣本數也會增加。在所有情況下,P值均假設為0.8。效應大小為0.2、1或2.5時的樣本大小[SS],分別是788、34和8。底部的圖形表示樣本大小變化對檢定力的影響。
圖4.效應大小和檢定力之間的關係。顯示了兩種不同的情況,其中樣本大小保持恆定在8或30。當樣本大小保持恆定時,研究的檢定力隨著效應大小的減小而減小。當效應大小為2.5時,即使8個樣本也足以獲得0.8的檢定力。當效應大小為1時,將樣本數從8增加到30會大大增加研究的檢定力。但是,如果效應大小低至0.2 ,則即使有30個樣本也不足以達到顯著的檢定力值。
特別是近年來,研究結果的臨床意義或有效性超過了統計學意義;了解效應的大小和檢定力已經獲得了巨大的重要性[35 - 38]。
有關假設的初步資訊對於在預期檢定力下,計算樣本數目非常重要。通常,這是通過根據先前研究或初步研究的結果,確定效應大小來實行的。有可用的軟體,可以使用效應大小來計算樣本大小
臨床研究前樣本數的確定
就樣本數而言,動物研究是最關鍵的研究。尤其是出於道德考慮,將樣本數保持在最低水準是十分重要的。應當指出的是,動物研究與人體研究有根本的不同,因為許多動物研究使用的雜交動物其遺傳背景極為相似。
因此,因為基因的不同對於研究結果的影響可保持在最低水準,因此該研究中所需的動物要少得多[39,40]。
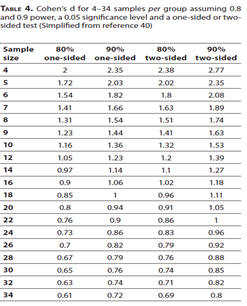
由此,針對每種研究類型建議了替代性的樣本數估計方法[41-44]。如果要使用先前或初步研究的結果確定效應大小,則可以使用G-Power進行樣本大小估計。此外,表4.也可用於容易的估算樣本數[40]。
除了可以根據表4.計算的樣本數估算值外,表1.中所述的公式和表2.中提及的網站,也可以用於估算動物研究中的樣本數。依靠先前的研究存在一定的局限性,因為不一定總是夠獲得可靠的“合併標準差”和“組平均值”。
Arifin。提出了更簡單的公式(表5.)以計算動物研究中的樣本數[45]。在組比較研究中,可以如此計算樣本數:N
=[DF / k]+1[公式4]。

根據自由度[DF]的可接受範圍,將公式中的DF替換為最小值[10]和最大值[20]。例如在一項實驗動物研究中,測試了使用3種研究藥物的最低動物數量:N
=[10/3]+1 = 4.3; N =[10/3]+1 = 4.3;
N =[10/3]+1 = 4.3; N =[10/3]+1 = 4.3。四捨五入為每組5只動物。總樣本大小=
5 x 3 = 15只動物。所需的最大動物數:N =[20/3]+1 = 7.7。四捨五入為每組7只動物,樣本總數=
7 x 3 = 21只動物。
總之,對於推薦的研究,每組將需要5至7只動物。換句話說,總共需要15到21只動物才能使DF保持在10到20之間。
在Ricci等的研究中。回顧了涉及動物模型的15項研究,注意到使用的樣本數平均為10[6到18之間],但是任何研究群組均未正式報告的檢定力分析。令人驚訝的是,評論中包括的所有研究都使用了參數分析,而沒有事先進行常態性檢定(即Shapiro-Wilk),來證明其統計方法的正確性[46]。
值得注意的是,可以通過將檢定力保持在0.8,並選擇單尾分析而不是兩尾分析來減少不必要的動物使用,如某些藥理研究中所進行的那樣,接受I型錯誤的風險為5%,從而減少了動物數量。所需動物數量減少14%[47]。
Neumann等提出了一種組序設計,以最大程度地減少動物的使用而不會降低統計檢定力。在這種策略下,研究人員僅對最初計劃納入研究的30%的動物進行了實驗。再對30%的動物進行中期分析後獲得的結果。如果沒有達到足夠的檢定力,則將另外30%的動物納入研究。如果最初60%的動物的研究結果,提供了足夠的統計能力,則其餘動物將被排除在研究範圍之外。如果沒有,其餘的動物也將包括在研究中。 據報導,這種方法平均可節省20%的動物,而不會導致統計檢定力下降[48]。
在不同的國家實施了替代的樣本數估計策略,用於動物測試。例如,德國西南部的一個地方當局建議,在沒有正式樣本數估計的情況下,每個實驗組的動物數量應少於7只,並且實驗動物的總數不應超過100只[48]。
另一方面,應該注意的是,對於每組8到10只動物的樣本數,除非預期到很大或非常大的效應大小(>
2),否則統計顯著性將無法實現[45,46]。這個問題仍然是動物研究的重要限制。像G-Power這樣的軟體可以用於樣本數量估計。在這種情況下,將需要使用先前或初步研究獲得的結果來進行計算。但是,即使文獻中已有先前的研究,將其數據用於樣本數估計仍會帶來不確定性風險。除非出版文章中提供了明確詳細的研究設計和數據。儘管研究人員建議可以通過諸如馬爾可夫鏈蒙特卡洛法(Markov
Chain Monte Carlo)之類的方法進行可靠性分析,但在這方面還需要進一步的研究[49]。
由美國國立衛生研究院(NIH),Nature
Puhishing Group and Science舉辦的聯合研討會的成果;“臨床前研究原則和準則報告”,在2014年發表,已經被許多組織與期刊承認。該指南對使用生物材料進行的研究(包括動物研究)以及基於圖像的數據處理[50]提供了重要的啟示。
有關動物研究的另一個重要點是使用技術重複(偽複製)而不是生物重複。技術重複是一種特定的重複類型,其中同一樣本多次量測,目的在探測與量測方法或設備相關的雜訊。在此,無論對同一樣本進行多少次量測,實際樣本大小都將保持不變。假設一個研究小組正在研究治療藥物對血糖水準的影響。如果研究人員量測接受實際治療的3隻小鼠和接受安慰劑的3隻小鼠的血糖水準,那將是生物學上的重複。
另一方面,如果將接受實際治療的一隻小鼠的血糖水準和接受安慰劑的一隻小鼠的血糖水準分別量測3次,這將是技術上的重複。兩種設計都將提供6個數據點來計算P值。但是從第二種設計獲得的P值將毫無意義,因為每個治療組只有一個成員(圖5.)。因此對N值無貢獻。對單隻小鼠的多次量測是偽複製。因此統計分析方法都無法在實驗後的階段修復選擇錯誤的重複樣本。在設計階段應準確選擇重複類型。這個問題是一個關鍵的局限性,尤其是在進行細胞培養實驗的臨床前研究中。對於已發表的研究結果進行嚴格的評論和評估非常重要[51]。這個問題大多被低估,掩蓋或忽略。這是引人注目的是,在一些出版物,實際樣品的尺寸被發現是低的甚至只有一個。在這種情況下,比較患者來源的幹細胞系中,藥物治療的實驗是特定的例子。儘管此類實驗可能有許多技術重複,並且實驗可以重複幾次,但原始患者是單個生物學實體。同樣地,當從一隻小鼠的前爪上收穫六個meta骨,並以六個單獨的培養基進行培養時,會進行另一次偽複製,其中樣本大小實際上是1,而不是6 [52]。Lazic等提出有幾乎一半的研究(46%)將偽複製(技術重複),而誤認為是真正的複制。,而有32%的研究沒有提供足夠的資訊來評估樣本數的適當性[53,54]。
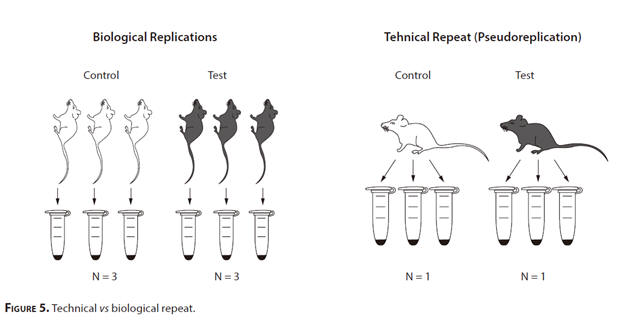
圖5.技術重複與生物學重複。
在研究提供定性數據(如電泳,組織學,色譜法,電子顯微鏡法),重複的次數(“數重複的”或“樣本數”)應該明確地指出。
特別是在臨床前研究中,在某些情況下和某些期刊中,經常使用平均值標準誤差(SEM)代替SD 。通過將SD除以樣本大小(N)的平方根來計算SEM 。SEM將指示如果整個研究重複多次,則其平均值將有多大差異。而SD是衡量一組數據中分數的分散程度的度量。由於SD通常高於SEM,因此研究人員傾向於使用SEM。然而SEM不是分配標準;SEM與95%信賴區間[信賴區間]之間存在關係。例如,當N
= 3時,95%信賴區間是幾乎等於平均值± 4
SEM,但是當Ñ ≥ 10; 95%信賴區間等於平均值± 2
SEM。標準偏差和95%信賴區間可用於報告統計分析結果,例如同一圖上的變化和精確度,以證明測試組之間的差異[52,55]。 考慮到研究期間實驗動物的磨損和意外死亡風險,通常建議研究人員將樣本數增加10%[56]。
Part 2. 一些遺傳研究的樣本量計算
樣本量對於遺傳研究也很重要。在遺傳學研究中,等位(allele)基因頻率的計算,基於Hardy-Weinberg原理的純合和雜合頻率的計算,自然選擇,突變,遺傳漂移,關聯,連鎖,分離,haplot型分析都是通過概率和統計模型進行的實施(57-6 2)。雖然G-power是有用的基本統計,分析大量的可利用遺傳檢定力計算器進行(http://zzz.bwh.harvard.edu/gpc/)(61 ,62 )。這個計算器,它提供(VC)與(QTL)連鎖和關聯測試的sibships自動檢定力分析,其他常見的測試中,尤其對於遺傳學研究分析複雜的疾病是顯著有效。
可以使用OSSE網站(http://osse.bii.a-star.edu.sg/)促進單核苷酸多態性(SNP)的病例個案控制研究。例如,讓我們確定病例和對照中SNPminor
allele基因頻率分別約為15%和7%。為了使檢定力為0.8而且具有0.05的顯著性,該研究要求包括病例和對照的239個樣本,總共需要578個樣本(圖6)。
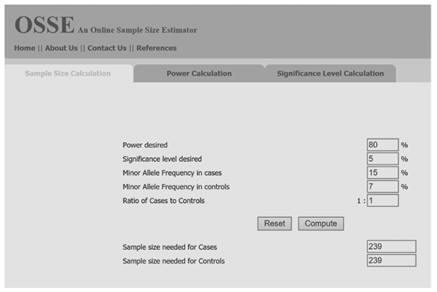
圖6.在線樣本量估計器(OSSE)工具的界面。(可訪問:http://osse.bii.a-star.edu.sg/)。
Hong和Park在他們的文章中提出了表格和圖形,以簡化樣本量估計(57)。假設5%的疾病流行的,5%的次要allele基因頻率和完整連鎖不平衡(D ' =
1 ),單個SNP標記,1:1控制-對照的情況,0.8的統計檢定力,和5%的I型誤差率條件下,樣本數目可以根據遺傳模型繼承[allelic,
additive, dominant, recessive, and co-dominant models]和的the
odd ratios of heterozygotes/rare homozygotes(表6)。如Hong和Park所展示的,在所有其他類型的繼承中,dominant
inheritance requires的樣本量最小

表6.
Number of cases required to achieve 0.8 power according to the different
genetic models and various odd ratios of heterozygotes/rare homozygotes
(ORhet/ORhomo) in case control studies to achieve 0.8 statistical power.
Whereas, testing a single SNP in a recessive inheritance model requires
a very large sample size even with a high homozygote ratio, that is
practically challenging with a limited budget (57). The Table 6
illustrates the difficulty in detecting a disease allele following a
recessive mode of inheritance with moderate sample size.
有效的樣本大小是根據所計算的以下假設:次要等位基因頻率為5%,疾病患病率是5%時,存在是完全連鎖不平衡(D ' =
1),對照外殼到控制比為1:1,和類型單標記分析的錯誤率是5%(57)。
臨床研究中的樣本量和檢定力分析
在臨床研究中,根據假設和研究試驗設計計算出樣本數。交叉研究設計和平行研究設計則採用不同的方法來估計樣本量。與臨床前的研究不同,大量的臨床期刊需要為臨床研究進行估計樣本量。
臨床研究用以計算樣本量的基本規則如下:
1.錯誤水準(alpha):它通常設定為<0.05。
樣本大小應該增加以補償效應量的減小。
2.檢定力必須>
0.8:樣本量應增加以增加檢定力。
檢定力越高,錯過實際效應的風險越低。
3.臨床意義:效應大小和所需的樣本量之間存在反比關係。為了檢測出較小的臨床效應差異,需要更大的樣本量,反之亦然。應通過效應大小,信賴區間和P值評估臨床意義(圖7)(65)。
4.相似度和等效性:證明相似性和等效性所需的樣本量非常低。
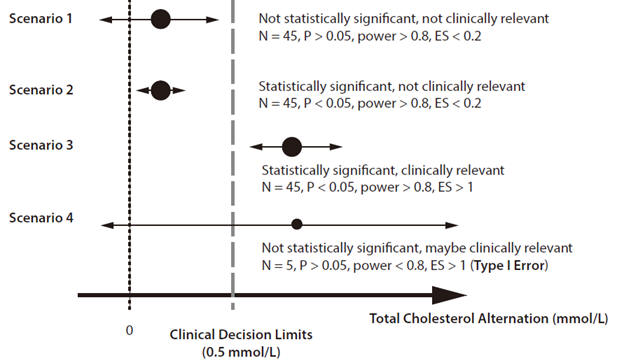

圖7.臨床意義,統計學意義,檢定力和效應大小之間的關係。
在以上示例中,為了提供臨床上顯著的效應,需要採取治療措施以使膽固醇的膽固醇水準至少降低0.5 mmol /
L。給出了四種不同的方案進行候選治療,每種方案均具有不同的總膽固醇平均變化和95%的信賴區間。
ES效應大小。N –參與者人數。改編自參考文獻65。
可以使用表1中的公式以及表2中的軟體和網站以手動進行樣本量估計(尤其是通過G-Power)。但是,所有這些計算都需要初步的研究結果或有關假設的最新研究成果。在複雜或混合研究設計中,估計樣本量很困難。此外:1)未有計劃的中期分析,b)有計劃的中期分析和c)對樣本大小估計可能需要有調整共同變數。
此外,進行研究後的事後檢定力分析(可以使用G-Power,PASS結合使用),顯著促進了臨床研究結果的評估。許多高品質的期刊都強調統計顯著性本身是不夠的。實際上,他們將需要根據效應的大小,臨床效應以及統計學顯著性意義對結果進行評估。為了充分理解效應大小。如表3所示,詳細了解研究設計並評估與統計檢定類型相關的效應大小將是有用。
因此,樣本量是規劃臨床試驗的關鍵步驟之一,樣本數估計值中的任何疏忽或不足都可能導致有效的藥物,過程或標記物被拒絕。由於統計概念在計算樣本量中有著十分重要的作用,因此足夠的統計專業知識對於這些重要的研究十分重要。
實驗室研究中的樣本量,效應大小和檢定力計算
在臨床實驗室中,可以使用G-Power,Medcalc ,Minitab和Stata等軟體進行群組之間比較(例如t檢定,Mann
Whitney U,Wilcoxon,
變方分析(ANOVA),Friedman,卡方(Chi-square等),相關分析(Pearson),Spearman等)和迴歸分析。
可以根據表3中提到的方法計算出的效應大小。這臨床實驗室中也很重要。但是,在研究差異性或關係性時,還必須考慮其他重要標準。尤其是根據多年經驗建立的指南(例如CLSI,RiliBAK ,CLIA,ISO文件)。以及從生物學變異研究中獲得的結果,主要為我們提供了有關效應大小的必要資訊和關鍵值,有時甚至是在樣本量的關鍵值。
此外,除了以統計顯著性(P值的解釋),不同的評價標準對於效應量也是一個重要的評估。這些指標包括精密度,準確度,變異係數(CV),標準偏差,總允許誤差,偏差,生物學變異和標準偏差指數等,並根據各種指南和參考文獻(66-70)進行了詳細說明。
以下將評估臨床實驗室中使用的某些分析類型的樣本量,效應大小和檢定力
在方法和設備比較的樣本量
用於方法比較中,樣本量對線性,Passing Bablok和Deming迴歸是重要決定因素,對Passing- Bablok和Deming方法相比的研究其樣本大小估計的於表7和表8。從表中可以看出,樣本量估算是基於斜率,分析精度(%CV)和範圍比(c)值(66-67)。對於一些不熟悉統計數據的研究人員來說,這些表似乎顯得有些複雜。因此,為了進一步簡化樣本量估計分法。參考文件和指南已準備並發布。
例如CLSI
EP09-A3指南,對於製造商將進行的驗證研究的最小樣本量,一般建議為100。而用戶進行驗證的最小樣本量為40(68)。此外,這些文件清楚地說明了在收集樣本以用於方法/設備比較研究時應該考慮的要求。例如,樣品應均勻地分散在整個檢測範圍內。因此,應該記住,隨機選擇的40-100個樣本數對於進行無可比擬的方法比較是不夠的(68)。
此外,在臨床實驗室中比較研究可能會使用於其他目的。例如設備間使用較少的樣本。建議編碼就足夠了。對於方法比較研究,將使用患者樣本。除了所需的重複次數外,CLSI文檔EP31-A-IR中還定義了樣本大小估計和檢定力分析方法。
在這裡臨界點是已知道的常數值差,內都運行的標準偏差,和總樣本標準偏差(69)。雖然有研究表明,分析設備具有較高的分析性能就可以減少樣本量。比較具有較低分析性能的設備的研究需要更大的樣本量。
Lu等使用最大允許的差異,以計算Blcand
Altuman比較研究所需要的樣本大小。這種類型的樣本大小估計,在實驗室醫學這是極為重要,能夠容易地進行使用MedCalc軟體(70)。

Slope - the steepness of a
line and the intercept indicates the location where it intersects an
axis. The greater the magnitude of the slope, the steeper the line and
the greater the rate of change. The formula for the regression line in
method comparison study is y = ax + b, where a is the slope of the line
and b is the y-intercept. The range ratio (concentration of the upper
limit / concentration of the lower limit). % CV - coefficient of
variation (analytical precision). *Sample size values are proposed for
respective slope ranges. i.e. for range ratio: 4, CV: 2%, slope range:
1.00–1.02 or
1.00–0.98 requires > 90 samples; whereas slope
range: 1.04-1.06 or 0.96-0.94 requires 40 samples. Note: In this
example, similar % CV values are assumed for the two methods compared.
For methods having dissimilar % CV values, the researcher should refer
to the reference 66.
表7.
Passing Bablok迴歸建議的樣本量大小,(檢定力至少為0.8,α=
0.05)(從參考文獻66簡化)

表8.
Passing和Weighend加權迴歸分析測試斜率偏離1或截距偏離零的必要樣本量
Type I error = 0.05. Power
= 0.9. Standardized Δ
value for slope = (Slope - 1) / CV. CV –
coefficient of variation. The range ratio - concentration of the upper
limit / concentration of the lower limit. CV refers to the CV at the
middle of the given interval (SD / mean of the interval for the analytes),
i.e. while the required sample size is 343 for a “standardized Δ
value for slope” of 1 for a range ratio of 2.5 in Deming regression, it
is 320 in weighted Deming regression (Simplified from reference 66).
批次間差異性研究的樣本量
眾所周知,批次間的差異可能會影響測試結果。為此建議進行方法比較,以監控批次改變之間所用試劑盒的性能。
協助估計這些研究的樣本量,CLSI準備了EP26-A指南“試劑間批次變化的用戶評估;批准的指南”,該指南提供了類似於EP31-A-IR(71,72)的方法。
表9列出了批次間變異研究的樣本量和檢定力,比較了3種不同濃度下的葡萄糖量測結果。在該示例中,如果葡萄糖量測差異值。不同批時是>
0.2mmol/ L,> 0.58 mmol/ L> 1.16mmol/ L。分析物濃度是2.7 7mmol/
L,8.32mmol/ L,16.65 mmol /
L ,可以確認批次是不同的。在每個濃度都使用一個樣本的情況下;如果從三個不同濃度中的每個濃度獲得的批次間差異結果低於拒收極限,這代表著測試批次的精密度值在接受極限之內,則該批次差異值為可在接受範圍內。而對於葡萄糖的量測值表示,在指南表明該。1個分析物濃度使用1個樣本,但應注意的是,樣品大小可能根據其設備而進行測試,也包括總允許誤差等。
對於不同的分析物和情況(即一種樣品/濃度不足的情況),研究人員需要參考CLSI
EP26-A(71)。
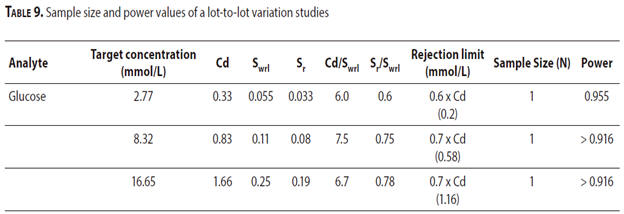
表9.批次間變異研究的樣本大小和檢定力值
Cd - critical difference is
the total allowable error (TAE) according to the CLIA criteria. Sr -
repeatability (within-run imprecision). Swrl- within-reagent lot
imprecision. Note: Sr and Swrl values should be obtained from the
manufacturer. Power is calculated according to critical difference,
imprecision values and sample size as explained in detail in CLSI EP
26-A. If the lot-to-lot variation results obtained from three different
concentrations are lower than the rejection limits when one sample is
used for each concentration (meaning method precision of the tested lots
are within the acceptance limits), then the lot variation is said to
remain within the acceptance range. (The actual table provided in the
guideline (CSLI EP26A) is of 3 pages. Since the primary aim of this
paper is to familiarize the reader with sample size estimation
methodologies in different study types; for simplification, only a
glucose example is included in this table. For different analytes and
scenarios (i.e. for occasions where one sample/concentration is not
sufficient), researchers need to refer CLSI EP26-A.) (71).
一些研究人員發現,在批次間差異和方法比較研究中(在一定程度上類似),CLSI EP26-A和CLSI
EP31估計樣本量方法相當複雜。相反地他們更喜歡使用Mayo Laboratori效應大小建議的樣本大小(重複次數)。Mayo實驗室決定在批與批之間的變化的研究可以,使用20人樣品進行其中數據分析。通過Passing- Bablok迴歸並根據下列標準: 的)斜率迴歸線將位於在0.9和1.1之間;b)R2
> 0.95;c)迴歸的截距線小於50%的報告濃度,d)試劑批次之差異平均值<10%(73)。 的)斜率迴歸線將位於在0.9和1.1之間;b)R2
> 0.95;c)迴歸的截距線小於50%的報告濃度,d)試劑批次之差異平均值<10%(73)。 |